안녕하세요, 넷마블 TPM실 기술분석팀 박정욱입니다.
HikariCP는 Java 애플리케이션에서 사용되는 고성능 커넥션 풀(Connection Pool) 라이브러리입니다.
대표적인 커넥션 풀 라이브러리들의 성능 순서
HikariCP > DRUID > Tomcat JDBC > Commons DBCP
HikariCP는 많이 사용되는 만큼 시스템 최적화를 위한 권장 설정 자료를 공식 사이트 또는 인터넷 검색을 통해서 쉽게 구할 수 있습니다. 하지만 대다수의 권장 설정 자료는 WAS(Web Application Server)와 DB(Database)로 구성된 시스템의 성능을 최적화하기 위한 것들입니다. 즉, 게임 서버 시스템을 위한 권장 설정은 전무하다고 할 수 있습니다.
이 글에서는 게임 서버 시스템을 위한 HikariCP 권장 설정값을 도출하기 위해서 반드시 이해해야 하는 JDBC와 Timeout을 우선 살펴보도록 하겠습니다.
JDBC 이해하기
HikariCP는 다수의 커넥션을 풀(Pool) 형태로 관리하는 역할만 담당할 뿐 DB와 통신하는 물리적인 연결은 별도의 Driver가 담당합니다. 이는 JDBC(Java Database Connectivity) API 규격에 따라서 DB와 물리적인 연결을 맺는 부분과 맺어진 연결을 관리하는 부분이 분리되어 있기 때문입니다. 따라서 HikariCP를 제대로 이해하기 위해서는 우선 JDBC를 이해해야 합니다.
JDBC의 동작 흐름을 일반화하여 그림으로 표현하면 다음과 같습니다.
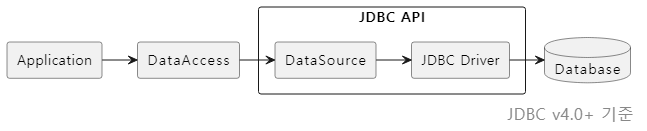
JDBC 기반의 애플리케이션 아키텍처는 크게 DataAccess 계층과 JDBC 구현 계층으로 구분할 수 있습니다. DataAccess 계층은 데이터 접근의 편의성과 일관성을 제공하고, JDBC 구현 계층은 DB와의 연결과 상호작용을 담당합니다.
DataAccess 계층
DataAccess 계층은 일반적으로 Repository 또는 DAO 패턴의 구현체를 의미하며, Persistence Framework 또는 Query Object 등의 구성 요소를 통해서 JDBC 구현 계층 중 DataSource와 상호작용합니다. 이를 그림으로 표현하면 다음과 같습니다.
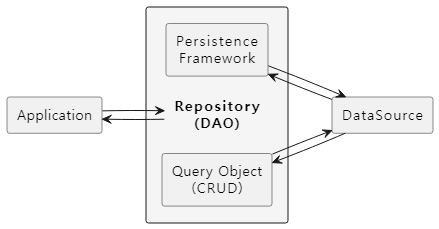
JDBC 기반의 애플리케이션에서 DB 데이터를 다루는 방식으로는 SQL을 직접 호출하여 CRUD를 수행하는 방식보다 Persistence Framework를 사용하여 직간접적으로 DB 데이터를 다루는 방식이 일반적입니다. 따라서 DataAccess 계층의 핵심 요소는 Persistence Framework라고 할 수 있습니다.
Persistence Framework는 SQL 문으로 직접 DB 데이터를 다루는 SQL Mapper와 Java 객체를 통해 간접적으로 DB 데이터를 다루는 ORM(Object-Relational Mapper) 방식으로 구분됩니다. 각 방식에 따른 대표적인 구현체들은 다음과 같습니다.
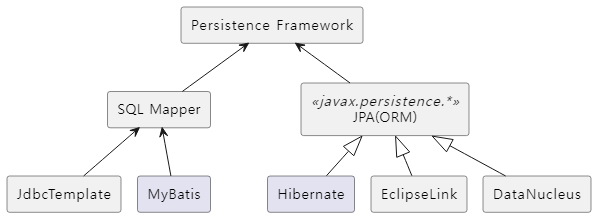
ORM 방식의 경우 SQL Mapper 방식과 달리 JPA(Java Persistence API)라는 표준 인터페이스를 통해 구현을 규격화하고 있습니다. 따라서 ORM 방식의 구현체들의 경우 동일한 인터페이스를 통해 접근 및 제어가 가능합니다.
SQL Mapper 방식에서 가장 인기 있는 구현체로는 MyBatis를 꼽을 수 있으며, ORM 방식에서 가장 인기 있는 구현체로는 Hibernate를 꼽을 수 있습니다.
JDBC 구현 계층
JDBC 구현 계층은 JDBC Driver와 DataSource로 구분할 수 있습니다.
JDBC Driver는 DBMS 벤더에서 정의한 네트워크 프로토콜을 사용하여 DB와 통신하는 역할을 담당합니다. 이러한 이유로 JDBC Driver의 구현체는 각 DBMS 벤더에서 제공됩니다.
DataSource는 JDBC Driver를 통해서 맺어진 DB와의 연결을 관리하는 역할을 담당합니다. DataSource는 DriverManager에서 발전된 형태로써 더 편리한 DB 연결과 커넥션 풀을 활용한 효율적인 DB 연결 관리 기능을 제공합니다. DataSource의 구현체는 각 DBMS 벤더 또는 OSS/서드파티를 통해서 제공됩니다.
JDBC 구현 계층에서 DB와 연결을 맺고 관리하는 과정을 그림으로 표현하면 다음과 같습니다.
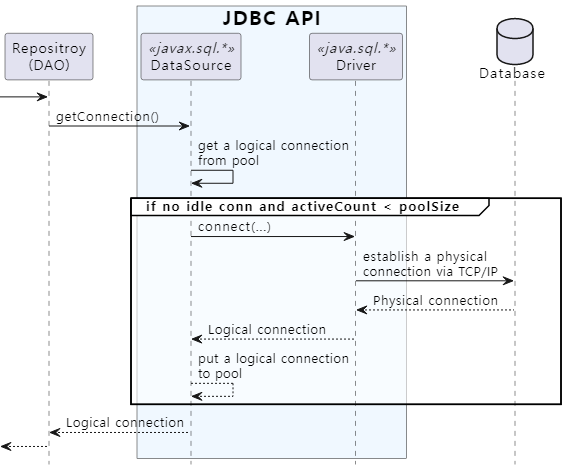
DataSource의 구현체는 앞서 설명한 대로 DBMS 벤더 또는 OSS/서드파티를 통해서 제공되며 대표적인 구현체들은 다음과 같습니다.
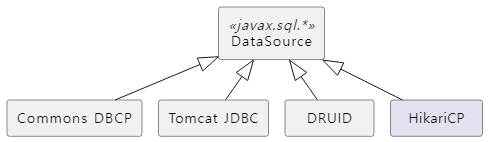
| JDBC DataSource Library | JDBC DataSource Class (Implementation) |
|---|---|
| Commons DBCP | org.apache.commons.dbcp.BasicDataSource (v1) org.apache.commons.dbcp2.BasicDataSource (v2) |
| Tomcat JDBC | org.apache.tomcat.jdbc.pool.DataSource |
| DRUID | com.alibaba.druid.pool.DruidDataSource |
| HikariCP | com.zaxxer.hikari.HikariDataSource |
DBMS 벤더에서 제공되는 JDBC Driver의 대표적인 구현체들은 다음과 같습니다.
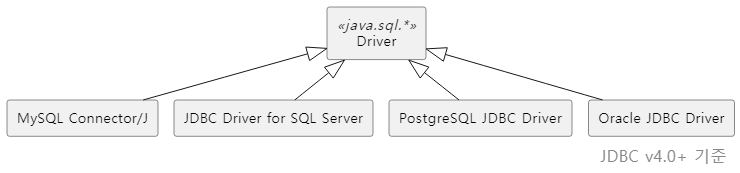
| JDBC Driver Vendor | JDBC Driver Class (Implementation) |
|---|---|
| MySQL Connector/J | com.mysql.cj.jdbc.Driver |
| JDBC Driver for SQL Server | com.microsoft.sqlserver.jdbc.SQLServerDriver |
| PostgreSQL JDBC Driver | org.postgresql.Driver |
| Oracle JDBC Driver | oracle.jdbc.driver.OracleDriver |
Timeout 이해하기
JDBC Driver는 네트워크 프로토콜을 사용하여 DB와 통신합니다. 이는 일반적으로 TCP/IP 연결을 의미하고, JDBC Driver가 TCP 소켓(이하 소켓)을 사용하여 DB와 통신하도록 구현된다는 것을 의미합니다. 따라서 소켓 통신에서 발생하는 Timeout은 JDBC Driver에서도 동일하게 발생합니다.
소켓 통신에서 발생할 수 있는 Timeout으로는 Connection Timeout과 Socket Timeout이 있습니다. Connection Timeout은 종단 간에 연결을 맺는 데 소요되는 시간의 임계치(threshold) 초과를 의미하며, Socket Timeout은 연결된 종단 간에 데이터를 주고받을 때 개별 패킷에서 소요되는 시간의 임계치 초과를 의미합니다.
참고: Java 소켓은 Write Timeout을 제공하지 않습니다. 따라서 Java 소켓 통신에서 발생하는 Socket Timeout은 Read Timeout만을 의미합니다.
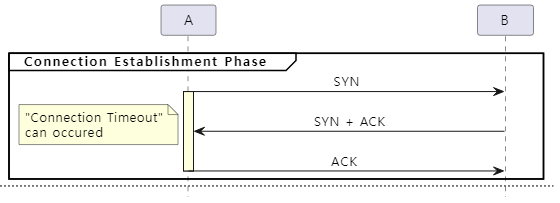
다음은 송신(A) 측에서 Connection Timeout과 Socket Timeout이 발생할 수 있는 구간을 그림으로 표현한 것입니다(예시는 HTTP 통신).
TCP 재전송
TCP 통신은 신뢰성을 보장하기 위해서 혼잡 제어(Congestion Control), 흐름 제어(Flow Control), 재전송(Retransmission) 등을 수행합니다. 이 중 재전송 처리 및 소요 시간이 소켓 통신에서 발생하는 Timeout에 영향을 끼칩니다.
TCP는 유실된 패킷을 재전송하기 위해서 재전송 타이머(Retransmission Timer)를 사용합니다. 재전송 타이머는 송신 측에서 패킷을 전송할 때 활성화되고, 송신 측이 수신 측으로부터 제시간에 ACK를 수신하면 취소됩니다. 이때 재전송 타이머의 시간 임계치를 RTO(Retransmission Timeout)라고 부르며, 이 RTO 시간 내에 송신 측이 수신 측으로부터 ACK를 수신하지 못하면 패킷 재전송이 발생합니다. 만약 재전송에 실패한다면 지정된 반복 횟수만큼 재전송이 시도되고, 재전송 시마다 RTO 값이 2배로 증가됩니다.
RTO 값은 두 종단 간의 RTT(Round Trip Time) 값이 측정되기 전까지는 initialRTO 값이 적용되고, RTT 값이 측정된 이후에는 측정된 값을 기반으로 동적으로 계산된 estimatedRTO 값과 minRTO 값 중 큰 값이 적용됩니다. OS별로 설정된 값은 다음과 같습니다.
- initialRTO 기본값
- Linux: 1000ms
- Windows: 1000ms
- 최신 버전이 아닌 경우 3000ms
- minRTO 기본값
- Linux: 200ms
- Windows: 300ms
- estimatedRTO 계산식(Jacobson Algorithm)
- estimatedRTO = SRTT + (4 \times RTTVAR)
estimatedRTO 계산식의 SRTT는 각 RTT의 가중 평균값인 Smoothed RTT를 의미하며, RTTVAR은 최신 RTT가 평균 RTT와 얼마나 차이 나는지를 나타내는 가중치인 RTT 편차(RTT variation)를 의미합니다. estimatedRTO 계산식을 어떻게 구성했는지 더 자세히 알고 싶다면 ‘Congestion Avoidance and Control’의 ‘Interaction of window adjustment with round-trip timing’ 부분을 참고하기 바랍니다.
TCP 3-Way Handshake와 재전송
RTT 값이 측정되려면 두 종단 간에 패킷이 왕복되어야 합니다. TCP 3-Way Handshake를 통해서 연결을 맺는 과정에서 SYN 패킷을 전송하고 SYN + ACK 패킷을 수신하게 되면 최초로 패킷이 왕복되고 RTT 값이 측정됩니다.
만약 이 과정에서 SYN 또는 SYN + ACK 패킷이 유실된다면 RTT 값을 측정할 수 없기 때문에 최초의 재전송 타이머는 initialRTO 값이 적용된 상태로 동작하게 됩니다.
다음은 SYN 또는 SYN + ACK 패킷 유실에 대한 재전송 타이머의 동작 방식을 그림으로 표현한 것입니다.
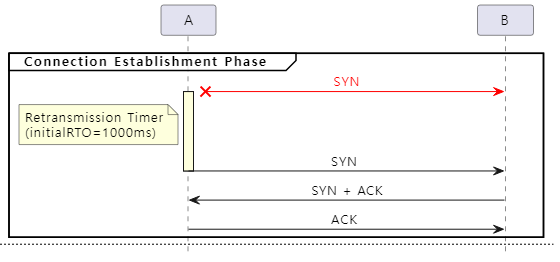
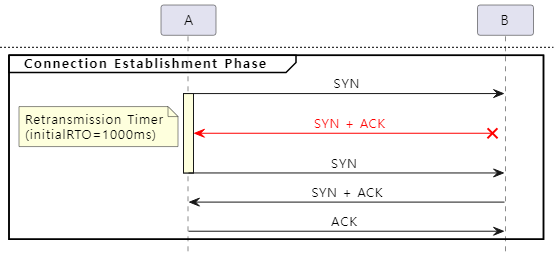
재전송 타이머는 SYN 패킷 전송 시 활성화되기 때문에 SYN 패킷 유실이든 SYN + ACK 패킷 유실이든 상관없이 initialRTO 시간 내에 송신(A) 측이 수신(B) 측으로부터 (SYN + ACK에 포함된) ACK를 수신하지 못한다면 SYN 패킷을 재전송합니다.
TCP 3-Way Handshake 과정에서 마지막 ACK 패킷이 유실된 경우에는 패킷 재전송이 발생하지 않습니다. 수신(B) 측은 다음에 수신하는 DATA 패킷을 통해서 ACK 번호를 알 수 있기 때문입니다. 자세한 사항은 RFC 793 Section 3.4를 참고하기 바랍니다.
initialRTO 값은 1초로 설정되어 있기 때문에 소켓의 Connection Timeout 값은 1초보다 큰 값으로 설정되어야 합니다. 만약 Connection Timeout 값이 1초로 설정된 상태에서 TCP 3-Way Handshake 과정 중 패킷 유실이 발생한다면 재전송이 시도되기도 전에 Connection Timeout이 발생하기 때문입니다.
TCP DATA 전송과 재전송
TCP 3-Way Handshake를 통해서 연결을 맺으면서 최초의 RTT 값이 측정되었기 때문에 이후의 DATA 패킷 유실에 대한 재전송 타이머는 max(estimatedRTO, minRTO) 값이 적용된 상태로 동작하게 됩니다.
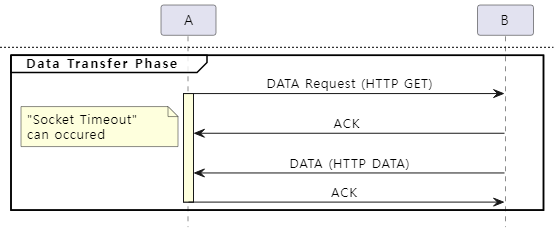
다음은 송신(A) 측에서 전송한 DATA 패킷이 유실된 경우에 대한 재전송 타이머의 동작 방식을 그림으로 표현한 것입니다.
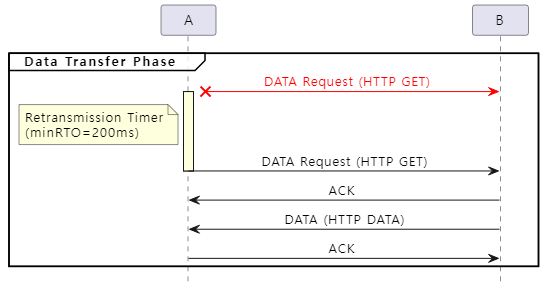
Connection Timeout에서 설명한 것과 동일한 과정으로 인해 Socket Timeout 값이 200ms로 설정된 상태에서 DATA 전송 과정 중 패킷 유실이 발생한다면, 재전송이 시도되기도 전에 Socket Timeout이 발생합니다. 따라서 Socket Timeout 값은 minRTO 값인 200ms보다 큰 값으로 설정되어야 합니다.
하지만 Socket Timeout의 경우 반드시 고려해야 할 다른 변수가 있는데, 바로 수신(B) 측에서 요청을 처리하기 위해 소요되는 Processing Time입니다. Socket Timeout의 경우 Write Timeout과 Read Timeout으로 구분되는데, Processing Time이라는 변수는 Read Timeout에 영향을 끼칩니다.
Request-Response 패턴 기반의 네트워크 프로토콜로 호스트와 통신하는 애플리케이션의 경우, 일반적으로 socket.send() API를 호출하여 Request를 전송하고 즉시 socket.recv() API를 호출하여 Response를 수신하는 동기 방식으로 구현됩니다. 만약 Read Timeout 값이 200ms로 설정된 상태에서 socket.recv() API를 호출한 후, 호스트로부터 200ms 이내에 아무런 데이터가 도착하지 않는다면 Read Timeout이 발생합니다.
비동기 소켓의 경우 Read Timeout을 처리하는 방법이 다르지만 Response를 수신할 때 Read Timeout이 발생되는 방식은 동일합니다. 그리고 대다수의 JDBC Driver의 구현체는 동기 소켓을 기반으로 구현되어 있습니다.
즉, 호스트가 요청을 처리하는 시간과 응답 DATA 패킷이 전송되는 시간의 합이 200ms 이내가 되어야만 Read Timeout이 발생하지 않습니다. 따라서 소켓의 Read Timeout 값은 호스트의 Processing Time과 minRTO 값의 합보다 큰 값으로 설정되어야 합니다.
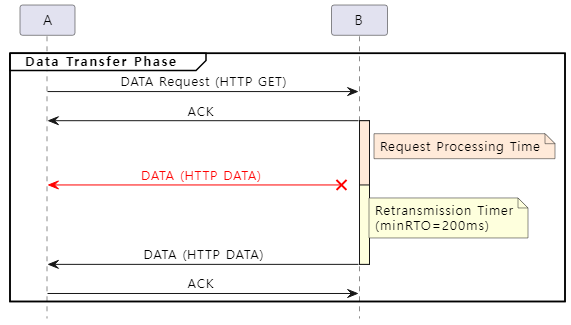
다음은 호스트(B) 측의 Processing Time과 응답 DATA 패킷 유실에 대한 재전송 타이머의 동작 방식을 그림으로 표현한 것입니다.
Statement Timeout과 Socket Timeout
JDBC Driver는 Socket Timeout과 별개로 Statement Timeout 기능을 제공합니다. Statement Timeout이 별도로 존재하는 이유는 각 Timeout의 목적 및 용도가 서로 다르기 때문입니다.
Socket Timeout의 목적은 호스트와 맺어진 물리적인 연결에서 네트워크 장애가 발생하였을 경우 이를 애플리케이션에서 감지하여 장애에 대한 예외 처리를 수행할 수 있도록 하는 것입니다. 반면 Statement Timeout의 용도는 DB에서 수행되는 SQL 문(Statement) 한 개의 수행 시간을 제한하는 것입니다.
JDBC 구현 계층에서 Statement Timeout과 Socket Timeout이 발생할 수 있는 구간을 그림으로 표현하면 다음과 같습니다.
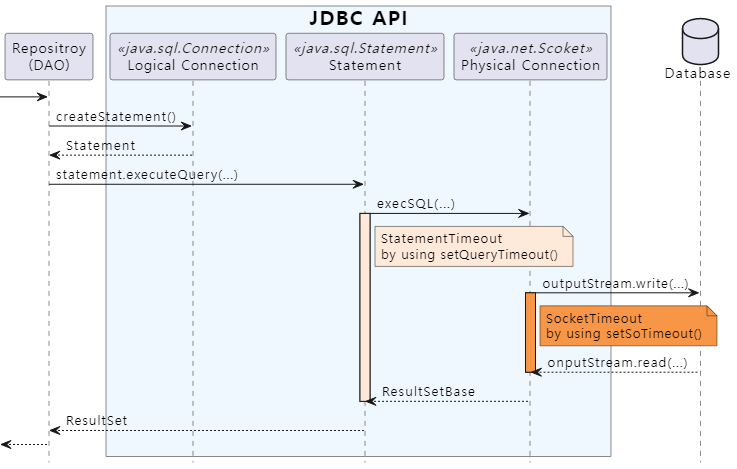
만약 네트워크 장애가 발생할 경우 DB와의 연결을 끊고 재연결하는 예외 처리를 목적으로 Statement Timeout 값을 3초로 설정했다고 가정해 봅시다. 설정 의도는 3초 내에 네트워크 장애를 감지하는 것이지만 실제로는 Socket Timeout 값만큼의 시간이 흐른 뒤에야 장애가 감지됩니다. 심지어 Socket Timeout을 지정하지 않아서 기본값인 0초가 설정된 상태라면 장애 감지가 전혀 되지 않을 수 있습니다.
반대로 슬로 쿼리(Slow Query)로 인해 응답 지연이 발생하는 것을 방지하기 위하여 Socket Timeout 값을 1초로 설정했다고 가정해 봅시다. 만약 1초 이내에 쿼리 실행이 완료되지 않는다면 의도대로 쿼리 실행이 취소되고 롤백이 수행됩니다. 하지만 이 쿼리 실행 취소 및 롤백은 DB와의 연결이 Socket Timeout으로 인해 끊어져서 수행된 것입니다. 즉, Statement 레벨로부터 SQL 실행 취소가 전달되어서 쿼리 실행 취소 및 롤백이 수행된 것이 아니기 때문에 정상적인 수행 절차라고 할 수 없습니다. 또한 DB와의 연결이 끊어졌기 때문에 재연결이 발생하고, Statement 레벨에서 쿼리 롤백이 한 번 더 실행되는 등의 사이드 이펙트가 발생할 수 있습니다.
그리고 Socket Timeout 값을 Statement Timeout 값보다 짧게 설정하고, Statement Timeout 이내에 실행이 완료되는 롱 쿼리(Long Query)를 실행했다고 가정해 봅시다. 이때는 위와 같은 이유로 쿼리 실행 시간이 Socket Timeout 값을 넘어가는 순간 DB와의 연결이 Socket Timeout으로 인해 끊어져서 실행 중인 쿼리가 취소되고 롤백됩니다.
이러한 이유로 Statement Timeout 값을 설정할 경우 반드시 Socket Timeout 값도 함께 설정해야 하며 Socket Timeout 값을 Statement Timeout 값보다 길게 설정해야 합니다.