안녕하세요, 넷마블 TPM실 기술분석팀 김범진입니다.
이전 글에서 메모리릭 수동탐지를 위해 덤프를 수집했었습니다. 이번 글에서는 수집한 덤프를 분석해 객체별로 수치화한 데이터를 추출하는 방법에 대해 알아보겠습니다.
데이터 수집
여기서는 WinDbg를 활용하면 됩니다. 사용에 앞서 디버깅 기호가 필요하니 디버깅 경로를 지정하겠습니다.
.sympath cache*{cache경로};srv*https://msdl.microsoft.com/download/symbols;{유저 pdb 경로}
‘.sympath’ 뒤에 있는 ‘cache’에는 디버깅 기호를 임시 저장할 폴더를 지정합니다. 다음으로 MS 기호 캐시 서버 경로를 입력하고, 프로젝트에서 생성한 기호 위치를 지정합니다. 입력이 끝났다면, ‘.reload’를 입력해 디버깅 기호를 미리 로딩합니다. 로딩이 끝나면 분석할 준비를 마쳤다고 할 수 있습니다.
예시에서는 MS에서 운영하는 기호 서버까지 캐싱했습니다. MS 기호 서버에서 캐싱한다면, 다운로드 시간이 상당히 걸릴 수 있습니다. 불필요하다고 판단하시면, 기호 서버 경로는 제거해도 됩니다.
Heap 확인
이제 애플리케이션이 사용하는 힙(Heap) 영역을 확인해 봅시다. 이때 사용하는 커맨드는 ‘!heap’입니다. 옵션으로 ‘s’를 입력하면, 애플리케이션이 사용 중인 힙 영역을 모두 볼 수 있습니다. [Reserv] 항목이 크게 잡혀있는 영역이 애플리케이션이 주로 사용하는 힙 영역입니다. 간혹 여러 개가 균등하게 출력되는 케이스도 있습니다. 이때는 크게 잡혀있는 영역 모두를 조사해야 합니다. heap 컬럼값은 사용 중인 영역의 시작 주소이며, 추후에 필요한 값입니다. 기록해 두고 다음으로 넘어가겠습니다.
!heap -s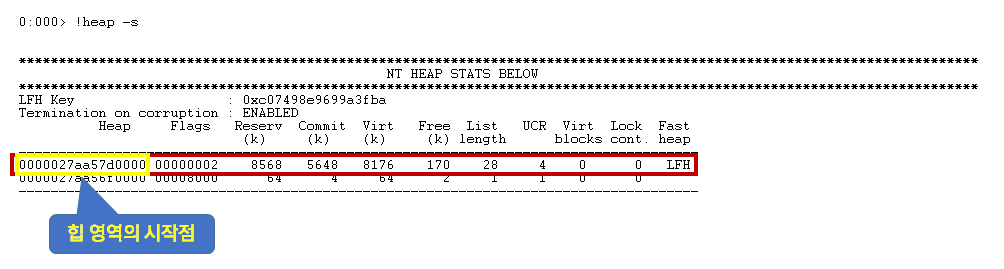
!heap -s 결과 화면애플리케이션이 사용하는 힙을 확인했다면, size별로 수치화한 데이터를 추출해보겠습니다. 이때 사용하는 명령어는 ‘!heap’에 옵션으로 ‘stat’과 ‘h’를 입력하고, 앞서서 봤었던 힙 시작 주소를 넣습니다.
!heap -stat -h {heap 시작 주소}아무런 추가 옵션이 없다면, 총 사용 크기 기준으로 내림차순 정렬된 상위 20개 데이터를 확인할 수 있습니다. 만약 전 범위를 조사하고 싶다면, ‘grp’ 옵션을 사용해야 합니다. ‘grp’ 옵션에는 A(size 기준), B(할당 개수 기준), S(총 메모리 사용량 기준) 등 세 가지 모드를 줄 수 있습니다. 여기서는 총 사이즈 기준으로 모든 범위를 출력하고 싶으니 ‘grp’ 옵션에 ‘S’ 모드를 입력하고 범위는 적당히 큰 범위를 입력했습니다.
!heap -stat -h {heap 시작 주소} -grp {option} {시작 index}n{종료 index}
!heap -stat -h {heap 시작 주소} -grp S 0n2000 범위를 지정할 때, 적당히 큰 값으로 2000을 입력하면 부족할 수도 있습니다. 상황에 따라 숫자를 늘리면 됩니다. 해당 명령 입력 결과는 화면과 같습니다.
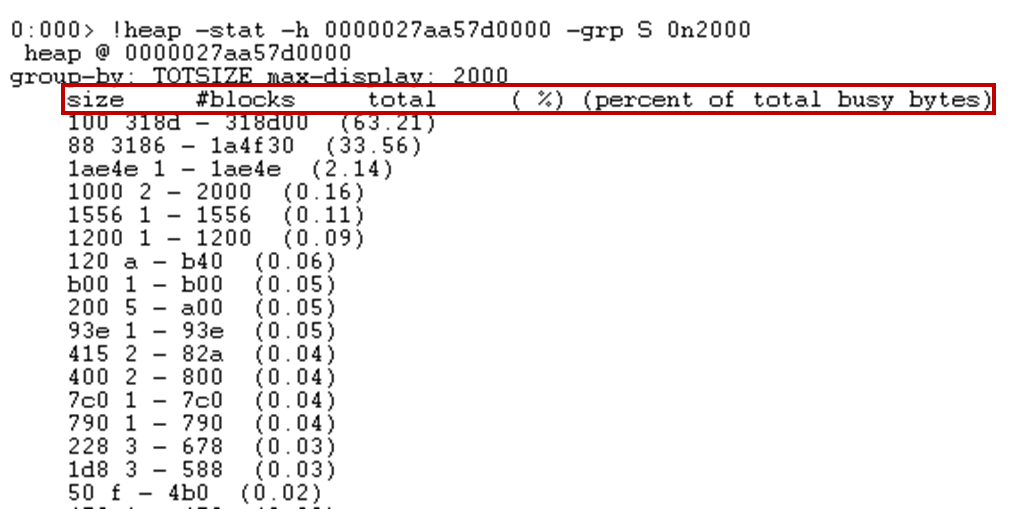
!heap -stat -h 0000027aa57d000 -grp S 0n2000 실행 결과각 컬럼의 의미는 다음과 같습니다.
- ‘size’: 실제 할당된 객체 혹은 메모리의 size를 나타냅니다.
- ‘#blocks’: 객체가 할당된 개수를 나타냅니다.
- ‘total’: size * blocks를 수치로 나타냅니다.
- ‘(%)’: 애플리케이션에서 얼마나 많은 비중을 차지하는지 비율로 확인할 수 있습니다.
여기서는 size별 할당개수를 추적해 메모리릭을 찾을 예정이므로, ‘size’와 ‘#blocks’값만 있어도 됩니다. 참고로 출력 결과는 모두 16진수 값입니다. 제일 상단에 있는 ‘size’가 100이라면 10진수 size는 256bytes입니다.
엑셀로 데이터 정리
WinDbg로 조사한 데이터는 텍스트 기반입니다. 실제 분석하기 위해 약간의 작업을 동반하는 데이터 정리가 필요합니다. 텍스트 기반 데이터를 간단히 정리하기 위해 엑셀을 활용해 보겠습니다.
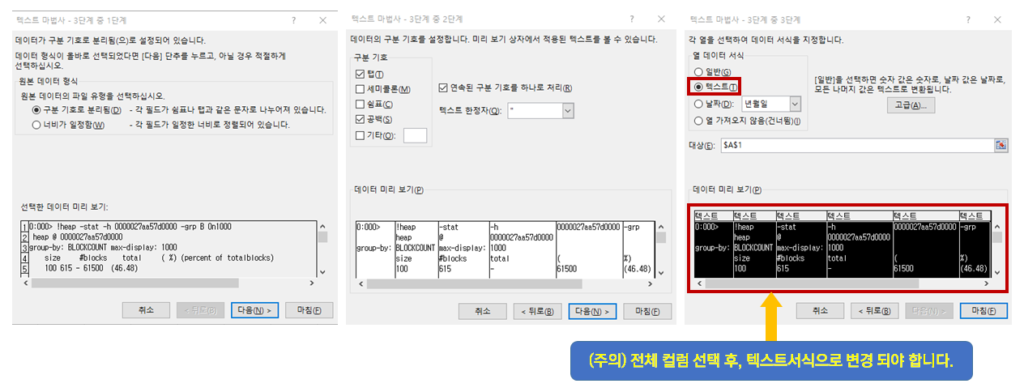
텍스트 데이터를 보면 공백으로 구분되는 규칙성이 있습니다. 엑셀에서 텍스트 나누기를 실행해 봅시다. 구분 기호로 분리됨 선택 후 다음으로 넘어갑니다. 구분 기호 항목에서 공백값(탭과 스페이스)을 선택하고, 연속된 구분 기호는 하나로 처리하는 옵션도 지정하고 다음으로 넘어갑니다. 여기서 주의할 사항이 있습니다. 엑셀에서는 자체 제공하는 기본 셀 서식을 사용합니다. 이 기본 셀 서식으로 인해 문자열을 셀에 입력 시, 16진수 데이터값 중 알파벳 e는 원래대로라면 십진수 14를 의미하지만, 엑셀에서는 자연 상수 e로 인식합니다. 이로 인해 10E5 라는 16진수는 1000000(1.00E+06) 이라는 데이터로 자동변환 됩니다. 원하는 출력이 되지 않습니다. 그 때문에 전체 열 데이터 서식을 텍스트를 변경해야 합니다. 데이터 미리 보기에서 전체 선택한 후, 서식을 텍스트로 변경해야지 정확한 데이터를 만들 수 있습니다.
위 방법을 이용해 수집한 모든 덤프 데이터를 WinDbg로 추출해, 시트로 옮깁니다.
비교 분석을 하기 제일 좋은 방법은 데이터를 시간순으로 정렬해 증가하는 개수를 찾아보는 방법입니다. 엑셀에서 vlookup을 활용해 수집 시간에 따라 증가하는 count를 한 시트에 넣습니다. 만약 10진수 표현이 필요하다면, hex2dec 함수를 활용하면 됩니다.
<HEX2DEC(VLOOKUP(찾을 데이터, ‘sheet명'!데이터범위, 2, FALSE))>분석
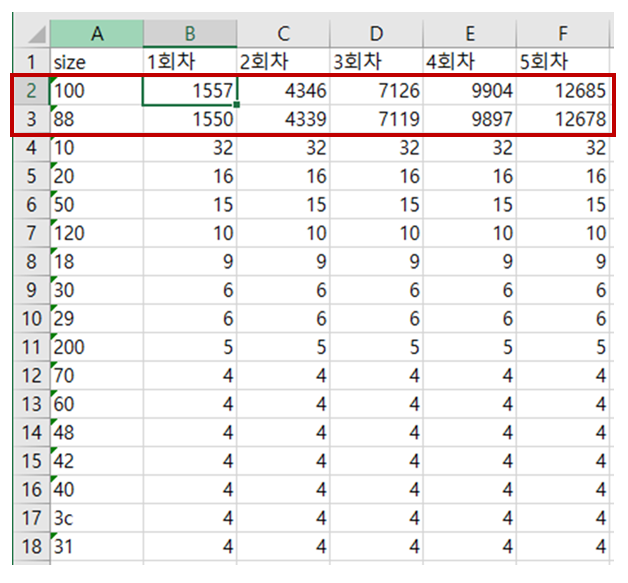
모든 덤프를 분석해 한 장에 모았습니다. 단계에 따라 계속 증가하는 수치가 보인다면, 그곳이 유력한 메모리릭 포인트입니다. 예시를 보면 ‘size’가 100인 곳과 88인 부분에서 단계에 따라 계속 수치가 증가하고 있는 것을 볼 수 있습니다. WinDbg를 활용해 ‘size’에 대한 힌트를 얻어보겠습니다.
다음 명령어를 입력하면, 특정 ‘size’에 대한 객체를 모두 출력할 수 있습니다. ‘flt’ 옵션을 넣고, ‘s’ 모드를 입력해 객체 size를 입력하면 됩니다.
!heap -flt s {16진수 size}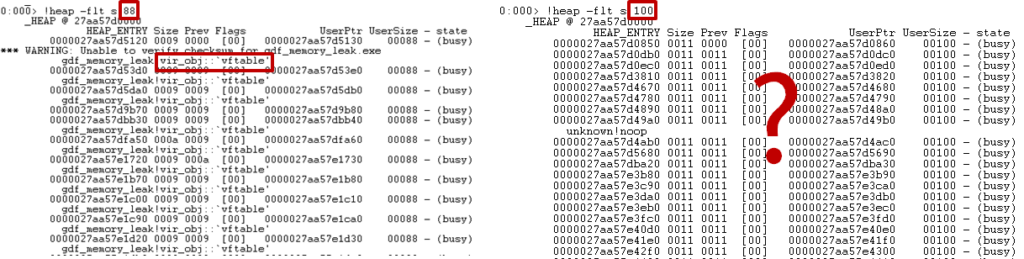
88 size와 100 size 결과 화면을 살펴보면, 88 size 결과에 ‘vftable’이 영향을 주고 있는 것을 볼 수 있습니다. ‘vftable’은 실제 호출할 함수를 찾기 위한 일종의 함수 포인터 테이블로, C++에서 가상화 키워드인 virtual과 연관됩니다. 예시 테스트 코드에서 ‘vir_obj’와 ‘obj’ 차이 중 하나로, 소멸자에 ‘virtual’ 키워드가 있고 없는 부분이 있었습니다. 이제 ‘virtual’ 키워드가 원인인지 확인하기 위해 ‘obj’ 소멸자에 ‘virtual’ 키워드를 붙여 재빌드해서 테스트해보겠습니다.
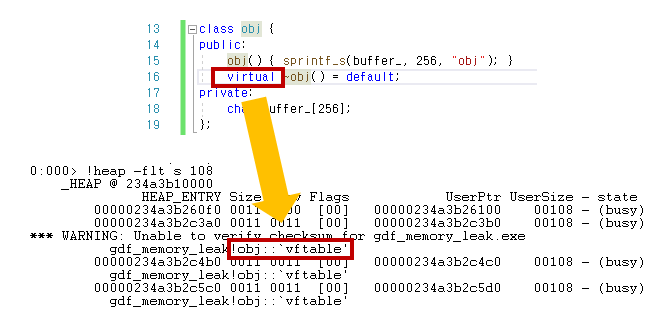
이제 ‘obj’에도 ‘vftable’이 보입니다.
실제 아무런 정보 없이 객체를 판별하려면 여러 어려움이 있을 것입니다. 하지만 이런 편법(?)을 사용하면, 큰 작업 없이 class의 태그로 활용할 수 있어 보입니다. 하지만 가상화의 특징으로 인해 사용 size가 100에서 108로 증가했습니다.
이런 태깅 방식을 라이브 서비스에서 활용한다면 추후 발행할 메모리릭에 편하게 대응할 수 있습니다만, 이 방법은 테스트 빌드에서만 사용할 것을 권장합니다. 가상 테이블의 특징상 함수를 호출하기 위해 테이블을 검색하고 호출하는 비용이 발생하므로, 실제 서비스에서는 쓸모없는 비용이 추가된다고 볼 수 있습니다. 또한, 가상화 함수는 최적화될 확률이 매우 낮습니다. 컴파일러는 함수 최적화 시에 성능을 위해 상황에 따라 호출보단 소스 전체를 본문으로 치환하는 경우가 있습니다.(inline 입니다.) 하지만 가상화한 함수라면, 치환할 확률이 매우 낮아집니다. (물론, 컴파일러에 따라서 최적화될 수도 있습니다.)
사용 메모리가 늘어난다는 것도 꽤 꺼림직합니다. 위 예시에서 가상화로 인해 size가 100에서 108로 8bytes 늘어났습니다. 단일 객체라면 문제가 되지 않지만, MMORPG에서는 상당히 많은 객체를 사용하므로 수십에서 수백MB 사용량이 증가할 우려가 있습니다.
‘virtual’ 키워드를 제거하면 꽤 최적화할 수 있어 보입니다. 하지만, 최적화를 위해 가상화 부분을 모두 삭제해버리면 더 큰 이슈가 생길 수 있습니다. 단적인 예로, 업캐스팅한 객체를 삭제하는 경우에도 메모리릭이 발생합니다. 그러므로 테스트에서만 태그를 활용할 수 있도록 개발 전략을 구상해야 합니다.
메모리 캐스팅
메모리릭이 어느 객체에서 발생했는지 힌트를 얻었으므로, 이제 왜 발생했는지를 분석해야 합니다. 대표적인 방법으로 메모리 실제 값을 보고, 데이터를 조사하는 방법이 있습니다. 88 size인 객체 ‘vir_obj’를 비주얼 스튜디오를 활용해 실제 데이터를 조사해보겠습니다.
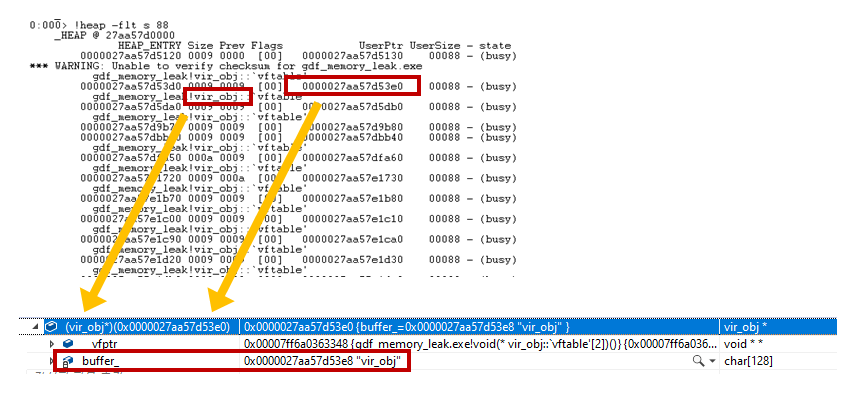
모든 사용 객체 조사를 위해 ‘flt’ 옵션으로 목록을 추출하면, ‘UserPtr’로 구분된 값을 볼 수 있습니다. 이것이 각 객체 시작 주소입니다. 이 주소를 비주얼 스튜디오에서 조사식을 활용해 변수 캐스팅을 하면, 실제 데이터 캐스팅이 된 것을 확인할 수 있습니다. 데이터 무결성을 판단하기 위한 스트링이 보인다면, 제대로 캐스팅된 것입니다.
할당되는 위치
객체가 할당되는 소스 위치를 찾는면, 매우 유리하게 소스를 검토할 수 있습니다. 하지만 아쉽게도 앞서 수집한 덤프로는 확인할 방법이 없습니다. 이때 WDK 10를 설치하면서 같이 설치된 GFlags를 활용합니다. GFlags 사용방법은 간단합니다. user stack trace 모드를 켜고, 충분히 구동한 후 덤프를 받으면 됩니다. ‘i’ 옵션을 넣고, 프로세스 이름 다음에 ‘+ust’를 입력하고 실행하면 됩니다.
gflags /i {process name} +ust (off는 -ust)
gflags.exe /i gdf_memory_leak.exe +ust 실행 결과하지만 주의사항이 있습니다. 옵션을 활성화하면 메모리를 할당할 때마다 콜 스택을 수집하기 때문에, 앞서 소개한 프로파일러첨 많은 성능 저하를 유발합니다. 그러므로 이것도 축소 테스트를 진행해 충분히 덤프를 수집한 이후, 비교 자료로 활용하면 됩니다. (덤프 수집 이후에는 꼭 ‘ust’ 옵션을 비활성화해야 합니다.)
이제 수집한 덤프를 다시 WinDbg로 로딩하고, 해당 size 객체를 사용하는 힙 영역 전체를 조사하겠습니다. 앞서 테스트와 동일하게 ‘vir_obj’의 사용 영역이 출력됩니다. 이제 할당되는 콜 스택을 확인해보겠습니다. ‘UserPtr’ 값을 랜덤으로 추출 후, heap 명령어를 활용합니다.
!heap -p -a {user heap address}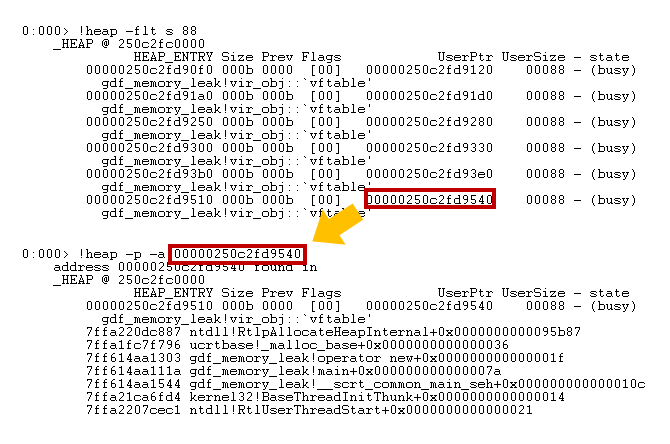
!heap -p -a 00000250c2fd9540 실행 결과이제 어디서 객체를 생성했는지 콜 스택을 볼 수 있습니다. (이때 같은 사이즈의 객체가 모두 동일한 스택을 나타내지 않을 수도 있다는 점을 주의해야 합니다. 메모리 할당은 한곳에서만 발생하면 좋겠지만… 그러지 않는 경우가 많습니다.) 데이터 몇 개를 샘플링해 스택을 확인하고, 해당 범위에 있는 소스를 검사해서 재차 확인해야 합니다.
소스 위치(Line)
콜 스택을 출력했지만 아쉽게도 함수명만 나옵니다. 이때 ln 명령을 사용하면 소스 코드 및 라인 번호를 확인할 수 있습니다.
ln {stack+offset}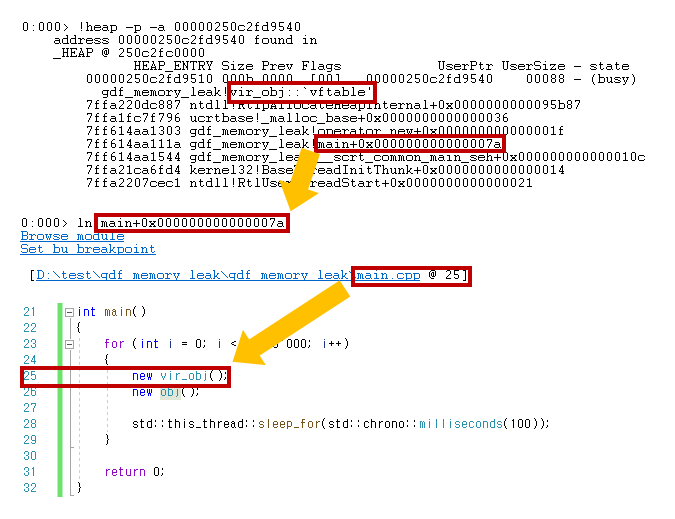
ln main+0x000000000000007a 실행 결과스택에 나오는 값은 “함수 진입점 + offset” 값이며, 이 값을 모두 복사해 인자로 입력하면 됩니다. 위 예시에서는 main.cpp의 25번째 줄이라 표시되며, 테스트 소스에서 25번째 줄에 해당 객체가 할당되고 있는 것을 확인할 수 있습니다.
여기까지 수동으로 덤프를 수집해 메모리릭이 발생하는 위치를 찾는 과정을 살펴봤습니다. 다음 글에서는 고질적으로 메모리릭을 유발하는 패턴인 “순환 참조(Circular Reference)”에 대해 알아보겠습니다.