안녕하세요, 넷마블 빅데이터실 모니터링서비스팀 심빈구입니다.
이전 글에서 옵저버빌리티(Observability)를 확보하기 위한 내용을 살펴봤습니다. 이번 글에서는 레거시 서비스에 로깅 기술을 적용한 후기와 로그 품질 개선 팁을 공유합니다.
레거시 서비스에 로깅 기술을 적용해보면
서비스 초창기부터 앞서서 소개한 로깅 기술을 적용해서 로그를 잘 활용하고, 로그 품질을 관리해왔다면 문제가 없을 것입니다. 하지만 레거시 서비스에 로깅 기술을 적용해보면 뜻하지 않은 문제를 겪게됩니다. 이는 그동안 로그 품질관리가 잘 되지 않은 탓입니다. 레거시 서비스에 로깅 기술을 적용할때 겪는 로그품질 문제를 몇가지 소개합니다.
제각각인 로그 레벨
에러 로그 추이만으로는 장애를 인지할 수 없다
회사나 조직에 로그 레벨이 표준화되지 않았거나, 표준화됐더라도 그대로 잘 개발됐는 지 관리하지 않았다면, 중앙집중식 로깅 방식을 적용한 후 에러(ERROR)나 경고(WARN)레벨인 로그 비율을 보고 깜짝 놀랄 수도 있습니다. 실제로 이런 케이스가 적지 않습니다. 아래 사례와 같이 경고 레벨이나 에러 레벨인 로그가 전체 로그에서 80% 이상 차지하는 경우를 흔치 않게 겪을 수 있습니다.
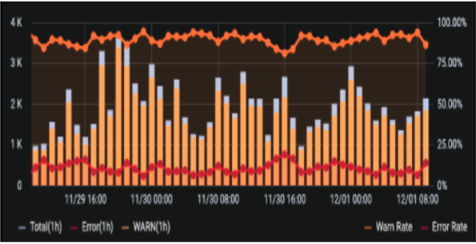

부족한 에러 레벨 로그 내용
문제가 발생했을 때, 디버깅을 할 수 없다
에러 로그에는 에러가 발생한 원인, 당시 상황, 스택 스택 트레이스(Stack Trace)를 자세히 남겨야 합니다. 그래야 해당 에러 로그를 보고 원인을 파악할 수 있습니다. 하지만 여러 이유로 에러 로그에 해당 내용을 누락하는 경우가 발생하고, 실제 장애가 발생한 후에야 누락했다는 사실을 발견하게 됩니다.
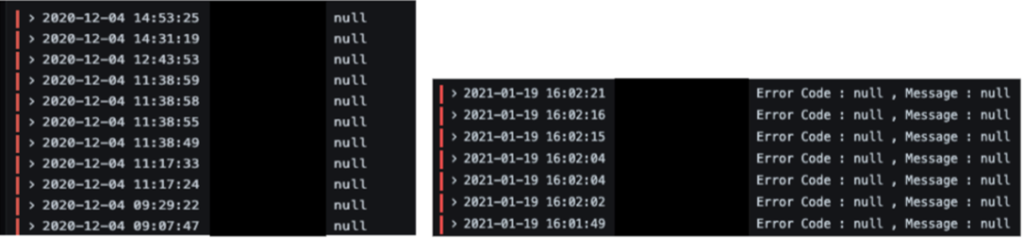
로그 본문에 포함된 각종 컨텍스트 정보
간단한 통계를 쉽게 뽑기 힘들다
과거에 작성한 코드는 대부분 비구조화된 로깅 포맷인 텍스트(Text) 포맷으로 로그를 다뤘기 때문에, 로그 본문에 각종 컨텍스트 정보를 포함시킨 경우가 많았습니다. 대표적으로 아래와 같은 형식입니다.
로그본문에 컨텍스트 정보가 있는 로그 사례
> Purchase successed : gameCode=aaa, userId=bbb, productCode=ccc
> Purchase failed : gameCode=aaa, userId=bbb, productCode=ccc, errorCode=TOKEN_EXPIRED위와 같은 로그 포맷으로는 중앙집중식 로깅을 적용하더라도, 해당 서비스가 제공하는 도구를 이용해 간단한 통계를 내기가 쉽지 않습니다. 대표적으로 ‘게임별 구매 실패 비율’ 또는 ‘구매 실패 에러코드별 비율’ 등을 꼽을 수 있습니다.
생각보다 자주 발생하는 스캐닝 공격
공개(Public)망에 오픈한 서비스를 운영하다보면, 스캐닝 공격으로 인한 에러가 생각보다 자주 발생하는 것을 경험할 수 있습니다.
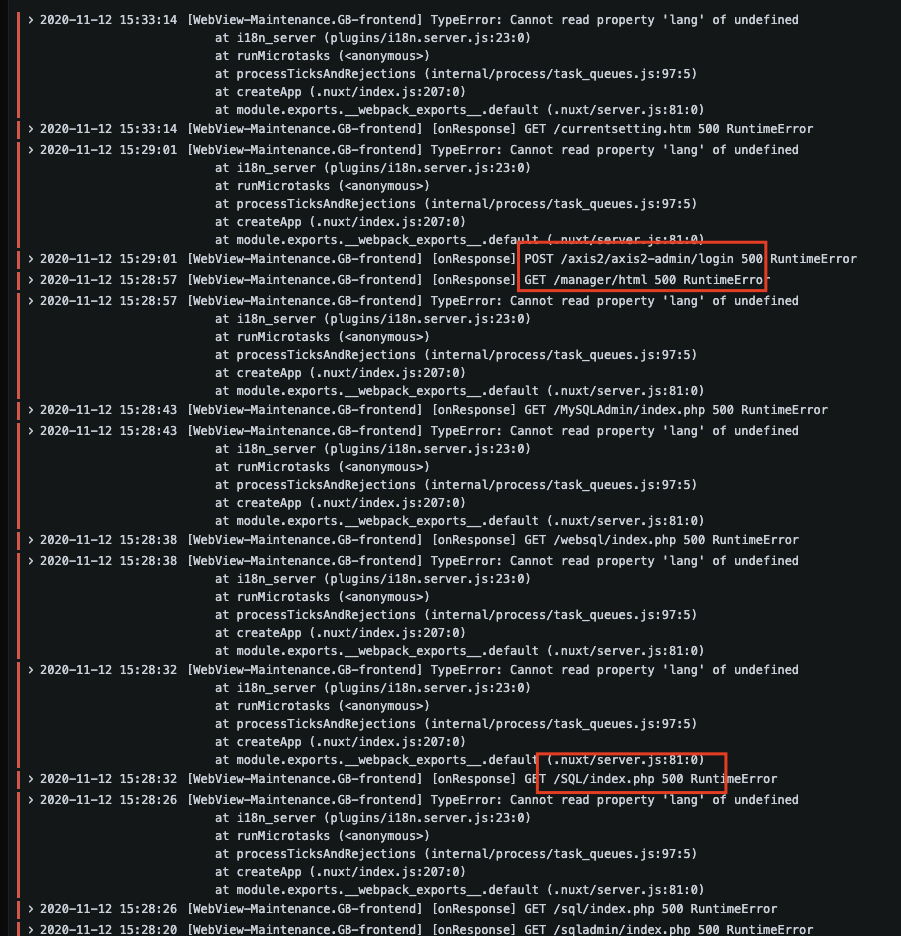
로그도 지속적인 개선이 필요하다
앞에서 살펴본 것과 같이 실제로 로깅 기술들을 적용해보면,
- 그동안 숨겨져 있던 로그 품질(기술부채)을 가시화할 수 있습니다.
- 다양한 예외 상황을 인지할 수 있습니다.
그래서 코드 리팩토링과 같이 애플리케이션 로그도 지속적으로 개선을 해야 합니다. 그렇다면 로그 품질개선을 위한 기준 원칙에는 어떤 것이 있을까요?
로그품질 개선 가이드 기본원칙
이 장에서는 여러 오픈소스의 권장 가이드를 종합해, 로그 품질개선에 참고가 될만한 기본 원칙 3개와 팁 7개를 소개합니다.
<가이드와 팁을 정리하는데 참고한 문서>
ⓛ권장 로그레벨
앞서서도 언급했지만, 중앙집중식 로깅을 통해 모은 로그를 동일 기준으로 다루기 위해서는 로그 레벨이 의미하는 바를 표준화하고, 모든 개발팀이 이를 준수하며 로그 레벨을 결정하는 과정을 거쳐야 합니다. 아래는 넷마블 로그 레벨 표준입니다. Error, Warning, Info, Debug 등 4단계로 구분하고 있습니다.
Error
Error(오류) 레벨은 서비스 동작에 이상이 있을 정도로 문제가 발생한 경우입니다. DB 커넥션 오류나, 디스크 저장 공간 부족 등의 상황이 이에 속합니다. Error 로그가 등장하면, 당일 근무시간 내에 운영 담당자가 확인 조치하고 해당 사항에 대해 공유해야 합니다. 동일한 Error가 반복해서 발생한다면, 근무시간 외라도 즉시 확인 조치해서 공유해야 합니다.
Warning
Warning(경고) 레벨은 서비스 동작에는 이상이 없지만, 추후 장애로 이어질 수 있는 문제가 발생한 경우입니다. 커넥션 재시도, 백업 서버로 변경 등의 상황이 이에 속합니다. Warning 로그가 등장하면, 발생량 추이를 확인해 1~2주 내로 확인 조치를 해야 합니다.
Info
Info(알림) 레벨은 시스템 동작 상에서 특정 작업이 정상적으로 수행됐음을 알려주는 경우입니다. 이때 단위 작업(Unit of Work)을 같이 알려줘야 합니다. 주로 서비스 시작 및 종료나 특정 단위 등록 및 삭제 등의 상황이 이에 속합니다. Info 로그는 정상적으로 완료한 작업양을 측정하거나, 시스템 환경이나 설정 정보를 확인할 때 사용합니다.
Debug
Debug(디버그) 레벨은 Info 로그에서 기록된 단위 작업의 상세한 단계를 기록합니다. 주로 개발 및 통합 테스트 단계에서 디버깅 용도로 사용하거나, 운영 중 문제 발생시 원인 파악을 위해서 사용합니다.
②로그를 읽는 사람을 고려하자
기존 방식에서는 서비스 로그에 SSH 접근을 할 수 있는 소수 인력만 볼 수 있었습니다. 그래서 소수 담당 인력만 해석할 수 있는 수준으로만 로그를 작성해도 충분했습니다.
중앙집중식 로깅을 적용하면, 로그에 대한 접근성이 올라갑니다. 로그 조회가 더이상 소수만 쓰는 전유물이 아니라는 의미입니다. 그래서 로그에 메시지를 남길 때, 좀 더 친절하게 읽을 사람을 고려해서 작성해야 개발자에게 오는 문의가 줄어들 수 있습니다. 더불어 로그를 활용하는 사례도 늘어날 수 있습니다. 실제로, 넷마블에서는 QA 진행시 서버가 출력하는 로그까지 확인하도록 테스트 케이스(Test Case)에 추가하기도 합니다. 이를 통해 QA 결과에 대한 신뢰도와 활용도 모두를 높일 수 있습니다. 결과가 성공이라면 좀 더 확신할 수 있고, 실패라면 서버에서 발생한 에러 로그도 같이 결과 리포트로 받아서 디버깅에서 참고자료로 쓸 수 있습니다.
③로그를 자주 보자
앞선 2개 가이드라인에서 로그 레벨과 로그 내용에 대한 중요성을 이야기 했습니다. 이는 한번에 달성할 수 있는 목표가 아닙니다. 서버에서 발생한 로그를 꾸준히 보면서 잘못된 레벨과, 모호한 로그 메시지를 찾아서, 다음 코드 릴리즈때 수정할 수 있도록 코드에 반영해야 합니다. 아래는 이를 위한 간단한 실행 전략 예시입니다.
- 매일 아침 출근시마다, 어제 우리 팀에서 운영하는 서비스에서 발생한 에러 로그를 확인해야 합니다.
- 신규 배포후, 몇일동안은 새로운 에러 로그 발생 여부를 확인해야 합니다.
로그품질 개선 가이드 팁
①에러/경고 로그
에러와 경고 로그에는 꼭 스택 트레이스와 콘텍스트를 넣자.
실제 로그를 들여다 보면, 에러 로그에 스택 트레이스를 의도치 않게 포함시키지 않은 경우가 종종 나옵니다. 주로 로깅 라이브러리를 잘 활용하지 못해서 발생한 결과입니다. 실제 에러가 발생해서 에러 로그가 발생 하더라도 스택 트레이스가 없다면, 대부분 원인을 찾지 못해 에러에 대응하기가 어렵습니다.
에러 또는 경고 로그에는 반드시 스택 트레이스를 넣어야 합니다.
- 추가참고자료 : Atlassian 로깅 가이드라인
②INFO 레벨 이상
INFO 레벨 이상(INFO, WARNING, ERROR) 로그에는 단위 작업(Unit of work)을 기록하자.
INFO 레벨 로그에 단위작업이 아닌 중간 진행상황 로그를 남길 경우, 실제로 로그를 조회하기 쉽지 않을 수 있습니다. 중앙집중식 로깅방식에서는 로그 조회 대시보드에서 여러 스레드와 호스트에서 수집한 로그가 섞여서 조회된다는 것을 감안해야 합니다. 또한 거의 동시에 발생한 로그라면 정확한 시간순으로 조회되지 않을 수도 있습니다.그래서 단위작업이 완료된 이후 상황을 요약해서 로그에 남기는 것이 필요합니다.
BAD
// 로직 중간 단계에서 DEBUG 수준 로그를 INFO 로그로 남기고 있는 예시.
// 대시보드에서는 여러 스레드(Thread)와 호스트(Host)에서 남은 로그가 섞인 채 조회된다는 점을 감안해야 함.
> 2020-11-17 15:35:34 [heimadall-admin-api-server] Resolved Department : DB팀
> 2020-11-17 15:35:34 [heimadall-admin-api-server] ownerUserDepartment : DB팀
> 2020-11-17 15:35:34 [heimadall-admin-api-server] ownerUserDepartment : DB팀
> 2020-11-17 15:35:34 [heimadall-admin-api-server] ownerUserDepartment : 기술보안팀
> 2020-11-17 15:35:34 [heimadall-admin-api-server] ownerDepartment : DB팀GOOD
// 단위 작업(Unit of work) 완료시, 필요한 정보와 결과를 로그로 남김.
Resolving OwnerDepartment for DB-Team.KR(292) OwnerUserDepartment : DB팀, DB팀, DB팀, DB팀, DB팀, DB팀, 기술보안팀, 기술보안팀,, OwnerDepartment : DB팀,, ResolvedDepartment : DB팀③에러코드 필드
에러 로그와 경고 로그에는 별도로 에러코드 필드를 추가하자.
운영하다보면 적지 않은 에러 로그가 발생해서 단순 에러 로그 트렌드만으로는 시스템 상황을 확인하기 힘들 수 있습니다. 발생하는 에러 로그 종류가 많다면, 에러를 세분화해서 트렌드를 볼 수 있도록 로그의 별도 필드에 에러코드(errorCode)를 추가해야 합니다. 그래야 group By를 통해 에러코드별로 트렌드를 분석할 수 있습니다.
④Group By용 필드
Group By용 필드를 분리하자.
앞 ③번과 연결되는 내용입니다. 대부분 중앙집중식 로깅 솔루션은 로그의 특정 필드를 이용해 Group By해서 트렌드를 보는 그래프 기능을 제공합니다. 만약 트렌드를 분리해서 보고 싶은 항목이 있다면 로그 본문에 추가하기보다는 명시적으로 필드를 분리해서 로그를 쌓기 바랍니다.
BAD
// 본문 안에만 os와 게임코드 정보를 포함
{ ..
“message”: “login failed : os=android, gameCode=banana”
..
}GOOD
// Group By용 필드를 별도 필드로 남김. 필요에 따라 본문에도 os와 게임코드 정보를 포함할 수 있음
{ ..
“message”: “login failed : os=android, gameCode=banana”
“mdc”:{“os" : “android”, “gameCode": “banana”}
}⑤로그 대시보드
통합 테스트 단계부터 로그 대시보드를 사용하자.
애플리케이션 로그를 많이 활용할수록 로그 품질을 볼 수 있고, 로그 품질을 개선할 수 있는 확률을 높일 수 있습니다.로그 품질을 높일 수 있다면 효율적으로 문제 상황을 대처할 수 있습니다.
우리가 개발하는 서비스는 통합 테스트 단계에서 버그 같은 많은 문제 상황을 대처해야 합니다. 이때부터 대시보드를 통해 로그를 활용할 수 있다면, 테스트 단계에서 생기는 각종 버그 원인을 찾기 위한 로그 활용 과정에서 내용이 부족한 로그와 레벨이 맞지 않는 로그를 자연스럽게 볼 수 있습니다. 즉, 버그 수정과 함께 로그 품질 개선도 동시에 진행할 수 있습니다.
⑥로그 발생 원인
에러 로그에는 가능하다면 원인을 넣자.
에러 로그는 가능한 친절하게 작성해야 합니다. 당장에는 로그 메시지가 불친절해도 원인 파악이 어렵지 않을 수도 있습니다. 하지만 시간이 지날 수록 기억이 희미해지기 때문에, 작성한 시스템이 뱉어낸 에러 로그를 봐도 원인 파악이 안 될 수 있습니다. ‘미래의 나’를 위해서라도, 또는 타 부서 사람들을 위해서라도 에러 로그는 증상뿐이 아닌 조치를 하는데 참고할 수 있도록 원인을 넣어야 합니다.
BAD
// 메시지에 문제가 발생했다는 사실만 명시함
Failed to update kong configuration.GOOD
// 메시지에 문제의 원인까지 명시하여, 문제를 해결할 수 있도록 가이드함
failed to update kong configuration: posting new config to /config: 400 Bad Request
{"fields":{"plugins":[{"config":{"scopes":"expected an array"}}]},"name":"invalid declarative configuration","code":14,"message":"declarative config is invalid: {plugins={{config={scopes=\\"expected an array\\"}}}}"}⑦필터링
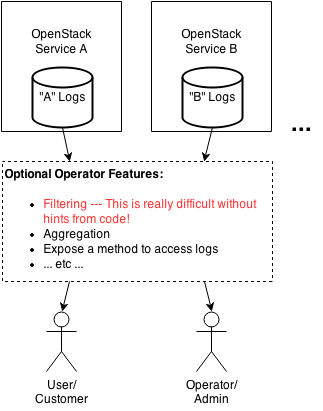
민감한 정보는 필터링하기 쉽게 해두자.
중앙집중식 로깅은 애플리케이션 서버에서 발생하는 모든 로그를 중앙 로그 저장소로 수집해 서비스합니다. 그래서 로그 안에 개인정보나 외부로 전송하면 안 되는 정보가 포함돼 있는 경우도 발생합니다. 만약 이런 정보를 외부 서비스로 전송하면 각 국가의 개인정보 보호법 등에 위배될 수 있습니다. 물론, 로그에 개인정보가 포함돼 있는지 자동으로 감지해서 해싱까지 해주는 주는 APM 솔루션이 있다면 문제를 바로 해결할 수 있습니다만, 현재까지 그런 솔루션은 없었습니다. 즉, 로그를 남기는 코드 작성 시에 이를 고려해서 작성해야 합니다.
오픈스택의 Security/Guidelines/logging guidelines에서는 이런 정보를 일반 로그와 구분할 수 있도록 태그를 활용하도록 가이드하고 있습니다. 구조적 로깅을 사용한다면, 이를 위한 별도 키(Key)를 지정해 로그에 표시를 할 수 있습니다. 이런 식으로 민감한 정보에 대해서 표시를 해둔다면, 로그 수집 시 해당 로그는 수집에서 제외하는 등 추가 설정을 할 수 있습니다.
마치며
점점 서비스 규모가 커지고 운영환경이 복잡해짐에따라, 여러 로깅 기술이 필요해지고 있습니다. 오픈소스나, 상용도구를 사용하면 이런 로깅 기술을 쉽게 적용할 수도 있습니다.
하지만 아무리 좋은 상용도구를 적용한다고 해도, 로그 품질을 잘 관리하지 않는다면, 앞서 살펴본대로 해당 기술을 적용해도 얻을 수 있는 장점을 충분히 얻지 못합니다. 로그 품질을 개선하는데 본 글에서 제시한 3가지 기본원칙과 7가지 팁이 많은 도움이 되길 바랍니다.
<References>
- Observability: A complete overview for 2021(Lightstep), https://lightstep.com/observability/
- How OpenTelemetry can improve Observability and Monitoring(Dynatrace), https://www.dynatrace.com/news/blog/how-opentelemetry-can-improve-observability-and-monitoring/
- What is Open Telemetry(Dynatrace), https://www.dynatrace.com/news/blog/what-is-opentelemetry/
- 오픈스택 로깅 가이드라인, https://docs.openstack.org/oslo.log/latest/user/guidelines.html
- 오픈스택 Confidential 정보 로깅 가이드라인, https://wiki.openstack.org/wiki/Security/Guidelines/logging_guidelines
- Atlassian 로깅 가이드라인, https://developer.atlassian.com/server/confluence/logging-guidelines/
- 로그레벨에 대한 의견(Stackoverflow), https://stackoverflow.com/questions/2031163/when-to-use-the-different-log-levels