안녕하세요, 넷마블 빅데이터실 모니터링서비스팀 심빈구입니다.
넷마블은 현재 수천개 VM과 수백개 K8S 클러스터 위에서 200여개 서비스를 운영하고 있습니다. 지금 이 순간에도 그 양은 점점 늘어나고 있습니다. 당연히 서비스 운영 환경은 기하급수적으로 복잡해졌고, 앞으로도 더 복잡해질 것입니다.
이번 글에서 이런 복잡한 서비스 환경에서 효율적인 운영을 끌어내기 위한 개념인 옵저버빌리티(Observability)를 알아보고, 넷마블에서 이를 이루는 요소 중 하나인 Logging을 도입하며 겪었던 시행착오와 가이드라인을 소개합니다.
복잡한 운영 환경과 Observability
서비스 규모가 커지고, 운영 환경이 복잡해지면 서비스 이상상황을 파악하기가 훨씬 어려워집니다. 어느 API가 평소보다 느려졌는지, 어느 부분에서 간헐적으로 에러가 발생하는지 찾는 자체가 새로운 난제가 됩니다. 옵저버빌리티(Observability, 관측 가능성, 가관측성, 관측용이성)는 이같은 이상상황을 효율적으로 파악하기 위해 등장한 개념입니다.
“옵저버빌리티는 단지 문제가 발생하고 있다는 것을 인지하는 정도를 넘어, 그 문제 발생 원인을 찾고 대처방안을 제시하는 수준까지 파악하는 것을 목표로 합니다.”[Lightstep Blog]
서비스를 관측하기 위해 서비스에서 로그(Log), 메트릭(Metric), 트레이스(Trace)라는 3가지 텔레메트리 데이터(Telemetry Data)를 수집합니다. 이 3가지 항목이 옵저버빌리티의 “3가지 기둥(Three pillars of observability)”입니다. 이 정보를 복합적으로 살펴보면 현재 서비스의 전반적인 상황이나, 문제 원인을 파악할 수 있습니다. 그래서 이 3가지 텔레메트리 데이터에는 서로 연관지을 수 있는 정보가 포함돼야 하고, 대시보드에서 이들 정보를 유기적으로 볼 수 있도록 만들어야 합니다.
이번 글에서는 옵저버빌리티를 구축하면서 도입하는 오픈소스나 상용도구의 기본정보뿐 아니라, 여러 시행착오를 로그, 메트릭, 트레이스 순으로 알아볼 것입니다.
로깅 기술 발전 History
로그 수집 방식
서버 로컬 저장소에 로그를 적재하는 방식
서버 로컬 저장소에 로그를 적재하는 방식은 아무런 도구를 사용하지 않고, 서비스를 운영할때 사용하는 방식입니다. 보통은 서버에서 발생하는 로그를 서버안 특정 디렉토리에 쌓도록 설정합니다. 서버 디스크 용량에 한계가 있으므로, 일반적으로 일정 용량이나 지정한 기간 이내동안의 로그만 남기도록 로테이션 설정을 해야 합니다.
이 방식에서는 보통 SSH로 서버에 직접 접근해 로그를 확인하므로, tail, grep, awk 같은 명령어를 잘 다루지 못하면 원하는 로그를 쉽게 찾기가 힘듭니다.
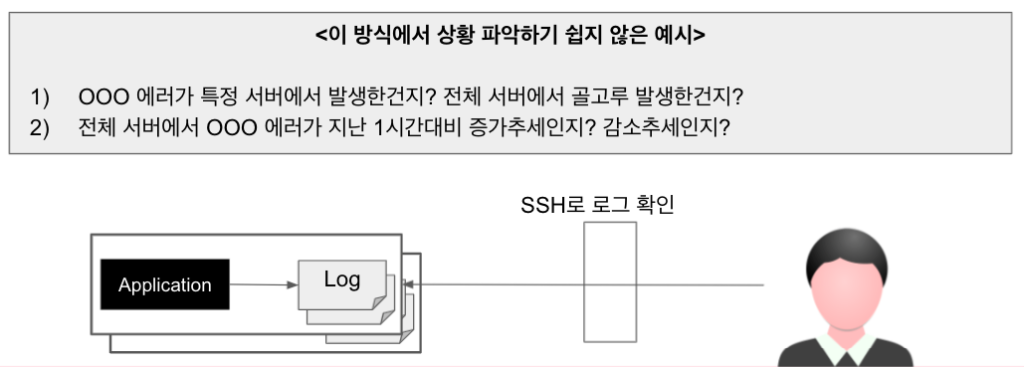
또한 MSA 환경에서는 문제를 확인하기 위해 봐야하는 서버 종류와 수가 늘어납니다. 그래서 장애가 발생하면 대응이 느려질 수밖에 없습니다.
최근에는 전세계적으로 개인정보보호와 정보보안에 대한 심각도가 높아졌고, 국내에서도 관련 시행령 등이 추가되거나 개정되면서 서비스 운영환경에서 여러 조치를 하고 있습니다. 특히, 망분리 환경에서는, 망분리 PC를 이용해야만 서버에 접근할 수 있기 때문에 더더욱 로그를 확인하기 힘듭니다.
쿠버네티스(Kubernetes, K8S) 같은 컨테이너 환경에서는 더욱더 이런 방식으로 로그를 다루기가 힘들어집니다. 컨테이너 내부에서 발생한 로그는 격리돼 있으므로 SSH로 직접 접근해 확인하기가 쉽지 않습니다. 그래서 kubectl 또는 별도 도구를 활용해서 파드(Pod)에서 발생시킨 로그를 조회해야 합니다.
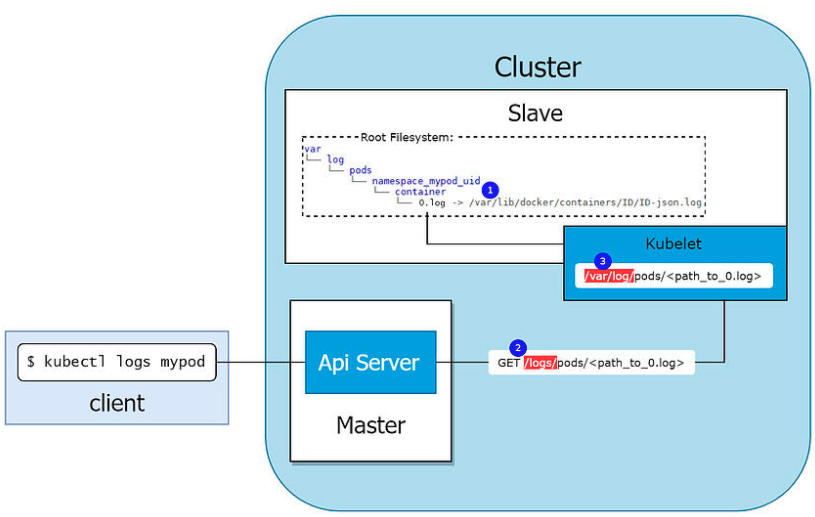
중앙집중식 로깅(Centralize Logging)
중앙집중식 로깅(Centralized Logging)은 서버 로컬 저장소에 로그를 적재하는방식에서 발생한 단점을 해결하기 위해 등장했습니다. 중앙집중식 로깅은 로그 수집 파이프라인(Pipeline)을 통해 서비스 로컬에서 발생한 애플리케이션 로그를 중앙 저장소에 수집합니다. 그래서 사용자는 단일 대시보드를 이용해 다수 서비스에서 발생한 로그를 검색하고 분석할 수 있습니다. 기존처럼 로그를 확인하기 위해 서버에 접근하지 않아도 되고, 분석을 위해 별도 명령어나 프로그램을 사용할 필요가 없습니다. 중앙집중식 로깅은 대다수 모니터링 솔루션에서 기본적으로 제공하고 있습니다.

중앙집중식 로깅 방식에서의 고려사항
중앙집중식 로깅을 도입하면 로그 조회 및 분석이 쉬워지는 장점을 누릴 수 있습니다. 하지만 여러 서버로부터 발생한 로그를 중앙저장소 한 곳에 모은 뒤에 대시보드를 통해 조회하는 구조이므로, 필연적으로 겪을 수밖에 없는 문제가 등장합니다.
중앙집중식 로깅 방식에서 마주할 문제
- 로그 수집을 위한 Agent(Sidecar)의 관리: 배포, 버전업, 설정변경, Agent 모니터링
- 로그를 한곳에 모았을때, 어떤 기준으로 분류(ex, 팀별 or 서비스별)해서 관리할 것인지
- 다양한 언어, 다양한 로깅 라이브러리를 통해 발생한 로그에서 로그레벨, 로그발생 시간, 에러코드, 스택 트레이스(Stack Trace, 스택 추적 기록) 등의 정보를 추출하는 일
1번문제를 해결하기 위해 각 APM 도구 제조사에서 자체적인 솔루션을 추가하고 있습니다. 하지만, 최초 설치는 별도 해결책을 찾아야 합니다.(예: Elastic의 Fleet)
2번문제를 해결하려면 사내 표준을 정의해야 합니다. 어떤 APM 서비스를 사용하던지 메타 정보를 추가할 수 있지만, 이 메타를 어떻게 할당할지에 대해 표준을 정해야 합니다.
3번문제를 해결하기 위해 초창기에는 Elastic의 GROK나 Graylog의 Custom Parser 같은 방안을 이용했었습니다. GROK은 비표준화된 로그 메시지를 원하는대로 파싱(Parsing)할 수 있도록 강력한 문법을 제공합니다. 하지만, 로그 포맷이 조금만 바뀌더라도 파싱 오류를 쉽게 겪을 수 있습니다. 또한, 다뤄야 하는 서비스 종류가 수백개가 된다면, 포맷 또한 그 수에 비례할 것이고, GROK이나 Custom Parser를 사용한다면 깨지기 쉬운 로직 수백개 유지보수를 감당해야 합니다.
아래 예시는 팀별 상이한 로그 포맷 과 GROK표현식 예시입니다.
1팀 로그 예시
2021-01-18T23:56:42.000+00:00 INFO [o.a.c.c.StandardService]:Starting transaction for session2팀 로그 예시
2021-01-18 09:07:06.179 INFO 50494 --- [ main] o.a.c.c.StandardService :Starting transaction for session 포맷별 Parsing 룰 예시
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log-level} \[%{DATA:class}\]:%{GREEDYDATA:message}" }
}구조적 로깅(Structured Logging)은 이 문제를 해결하기 위해 소개된 개념입니다. 다음절에서 이에 대해서 자세히 다루도록 하겠습니다.
구조적 로깅(Structured Logging)
위에서 나온 문제를 해결하기 위해 구조적 로깅(Structured Logging)이 등장했습니다. 구조적인 로깅은 사람이 읽을 수 있는(Human Readable) 로그 형식이 아닌, 기계가 읽을 수 있는(Machine Readable) 로그 형식을 사용하는 방식입니다. 참고로 거의 대부분 구조적 로깅 지원 라이브러리나 서비스에서 Json 포맷을 차용하고 있습니다.
비구조적 방식의 로그 예시
2021-01-18 09:07:06.179 INFO 50494 --- [ main] o.a.c.c.StandardService :Starting transaction for session구조적 방식의 로그 예시
{
“time” : “2021-01-18T23:56:42.000+00:00”,
“logger” : “o.a.c.c.StandardService”,
“level” : “INFO”,
“message” : “Starting transaction for session”
}구조적 로깅을 이용하면 로그에 상품코드나 게임코드 같은 필드를 간편하게 추가할 수 있습니다. 물론 이런 정보를 로그 본문에 추가하더라도 검색은 할 수 있습니다만, 별도 필드로 이런 정보를 추가하면, Group By를 통해 추이를 훨씬 쉽게 확인할 수 있습니다. 이 부분은 다음 글에서 다시 다루겠습니다.
비구조적 방식에서 필드 추가?
2021-01-18 09:07:06.179 INFO 50494 --- [ main] o.a.c.c.StandardService :Starting transaction for session구조적 방식에서 필드 추가
{
“time” : “2021-01-18T23:56:42.000+00:00”,
“logger” : “o.a.c.c.StandardService”,
“level” : “INFO”,
“message” : “Starting transaction for session”,
“playerId” : “OOOO”,
“상품코드” : “PROD1”,
“게임코드” : “banana”, ...
}구조적 로깅을 위한 표준
이같은 구조적 로깅을 활용하더라도 Json의 키(Key)가 서비스마다 다르다면, 여전히 중앙집중식으로는 다루기 힘들겁니다. 로그 메시지, 레벨, 시간, 추가 태그 등을 나타내는 키가 서비스 또는 팀마다 다르다면, 하나의 대시보드를 통해 조회하기가 불가능에 가깝습니다.그래서 회사나 조직내에서 공통으로 사용할 로그 포맷 표준을 정의하는 것은 매우 중요합니다. 이미 몇몇 표준이 있으므로 각자 회사나 조직에서 표준을 정할 때 참고하시기 바랍니다.
로그 포맷 표준 정의 사례
- Graylog Extended Log Format(GELF)
- Google Cloud’s operations suite(stackdriver)
- Elastic Common Schema(ECS)
- Open Telemetry
넷마블에서는 Open Telemetry를 검토했으나, 도입 시점 기준에서는 완성도와 적합도가 떨어져서, Elastic Common Schema를 기반으로 로그 포맷 표준을 정의하고 있습니다.

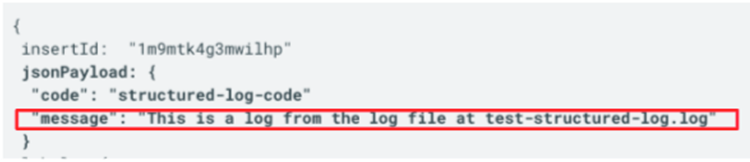

MDC(Mapped Diagnostic Context)
중앙집중식 로깅 방식에서는 수십 수백 개 서버에서 발생한 로그를 한 곳에 모으기 때문에, 원하는 로그를 검색하기가 어렵습니다. 그래서 조건값을 추가해 로그를 검색해야 합니다.
MDC는 이런 문제를 풀기 위해 로깅 라이브러리(Library)가 지원하는 기능 중 하나로, 현재 스레드(Thread)의 컨텍스트 정보를 유지한 채로 로그가 발생하는 시점에 자동으로 컨텍스트 정보를 추가합니다. Java의 Slf4J뿐 아니라, 다른 랭귀지에서도 라이브러로 개발하거나(C#, Python) 대안(node, golang)으로 여러 방법을 논의하고 있습니다.
MDC를 적용할 경우, 로그에 기록되는 항목이 늘어나고, 자연히 다시 파싱 문제가 발생하게 됩니다. 그래서 MDC는 보통 구조적 로깅과 같이 사용합니다.
로깅 기술 발전 History 요약
옵저버빌리티의 3가지 기둥 중 로깅은 코드를 수정하지 않아도 빠르게 서비스에 반영할 수 있습니다. 중앙집중식 로깅, 구조적 로깅, MDC 등 3가지 기술을 다 적용하면 다음과 같은 장점을 얻을 수 있습니다.

로그 품질을 관리할 수 있다
그동안 애플리케이션에서 발생하는 로그는 주로 문제가 발생한 경우에만 봤었습니다. 서버에 접속해야 하기도 하고 조회도 쉽지 않기 때문에, 개발시 의도했던 대로 로그가 제 역할을 하고 있는지를 확인하려면 적지 않은 노력을 들여야 했습니다. 막상 문제가 발생해 열어볼 때조차 원하는 정보가 로그에 찍혀있지 않거나, 필요한 로그가 없거나 하는 문제를 겪기도 했었습니다.
이제 로그를 통해,
- 장애를 인지할 수 있습니다.
- 문제 발생 시 디버깅이 쉬워졌습니다.
- 간단한 통계는 로그를 통해 뽑을 수 있습니다.
다음 글에서는 레거시 서비스에 로깅 기술을 적용하면 겪는 상황과 개선 가이드를 공유드리겠습니다.