안녕하세요, 넷마블 QA실 성능QA팀 남태희입니다.
성능 QA팀에서는 안정적인 게임 서비스 제공을 위해, 게임 출시를 앞두고 서버 성능을 테스트하며 개선 포인트를 도출하고 있습니다. 이번 글에서는 CPU 사용률이 높지 않은데도 쿠버네티스 파드가 계속 중단되고 재가동했던 이상 현상을 공유합니다.
쿠버네티스 파드 비정상 동작 상황 출현
노드의 CPU 리소스가 부족하거나 설정한 한곗값을 넘어서는 경우, kube-scheduler는 해당 노드에 추가 파드를 배치하지 않습니다. 이 말은 가용 범위 내에서는 노드 안에 있는 파드는 정상 동작해야 하며, 리소스가 남아있는 경우라면 파드가 추가 배치될 수 있다는 의미가 되기도 합니다.
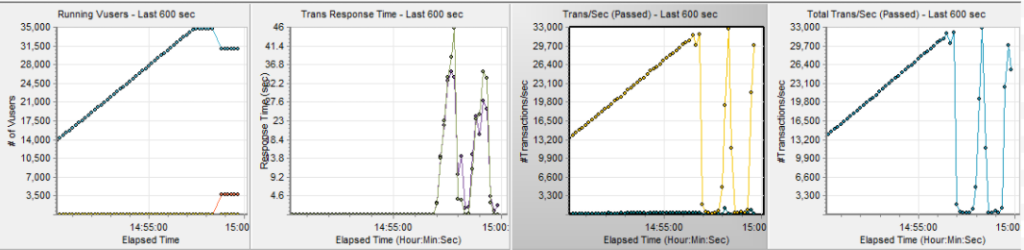
통상적으로 CPU 사용률이 40%라면 파드가 더 생성되더라도 부하를 수용할 수 있을 정도라고 볼 수 있습니다. 하지만 성능 테스트 중에 응답시간이 증가하며 파드가 중단되고 재가동을 반복하는 현상이 등장했습니다. 정상 동작 상황에서는 부하가 줄어들지 않는 한, 오토스케일링 규칙에 따라서 파드는 계속 유지되거나 늘어나야 합니다.
네트워크 부하로 인한 헬스체크 실패
30,000TPS를 계속 유지하면서 발생하는 현상을 더 세부적으로 살펴보기로 했습니다.
부하는 꾸준히 유지하고 있는 중이므로, 최초에는 이 부하를 소화하기 위해 오토스케일링에 맞춰 파드 개수가 늘어납니다. 불현듯 어느 순간 파드가 중단되면서, 전체 파드 개수가 줄어듭니다. 파드 개수는 줄어들지만 부하는 계속 유지되고 있으므로, 남아있는 파드의 평균 CPU 사용률이 올라갑니다. CPU 사용률이 올라가므로 이를 분산 소화하기 위해, 오토스케일링을 시작합니다. 오토스케일링 규칙으로 파드 생성 조건이 충족되고, 다시 파드가 새로 생성됩니다. 하지만 새로 생성한 파드가 유지되지 못하고, 다시 파드가 중단되는 사이클을 반복하고 있었습니다.
파드가 중단되는 원인을 찾던 중 쿠버네티스 헬스체크 기능이 비정상동작하고 있음을 발견했습니다. 우리가 사용하던 쿠버네티스 헬스체크 방식은 HTTP 방식이었는데, 네트워크 부하로 인해 컨테이너 상탯값을 제대로 받지 못하고 있었습니다. 컨테이너 상탯값을 받지 못한 파드에 ‘비자발적 중단’이 발생하며, 비정상동작을 반복했던 것이었습니다.
쿠버네티스 파드 라이프사이클에 대한 자세한 내용은 공식 문서를 참고해주세요.
영문 문서: https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
한글 문서: https://kubernetes.io/ko/docs/concepts/workloads/pods/pod-lifecycle/
특정 코어에 부하가 집중
쿠버네티스 클러스터에 있는 워커 노드에서 ‘top’ 명령어를 입력하면 CPU 코어별 사용량을 상세히 조회할 수 있습니다.
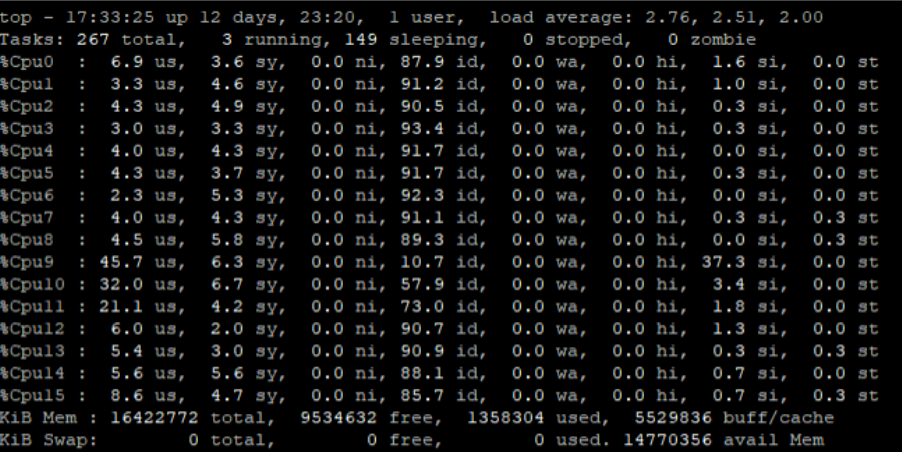
비정상 동작 상황이 출현했을 때 ‘top’ 명령어를 실행한 후, ‘1’을 입력하면 코어별 사용량을 조회할 수 있습니다. 이번 사례에서는 특정 코어(9번)에 부하가 집중되는 현상을 확인할 수 있었습니다.
RPS를 설정해서 2개 코어로 분산
RPS(Receive Packet Steering)는 수신한 패킷을 처리할 때 발생하는 네트워크 부하를 여러 CPU 코어로 분산시키는 역할을 하는 프로토콜입니다. 이를 활용해 특정 코어에 부하가 집중되는 현상을 분산시키기로 했습니다.
큐(Queue) 확인
$ ls -al /sys/class/net/<device>/queues/
total 0
drwxr-xr-x 4 root root 0 Nov 24 13:56 .
drwxr-xr-x 5 root root 0 Nov 24 13:56 ..
drwxr-xr-x 3 root root 0 Nov 24 13:57 rx-0
drwxr-xr-x 3 root root 0 Nov 24 13:57 tx-0
‘queues’ 디렉터리를 열어보면, 하위 디렉터리 2개를 볼 수 있습니다. ‘rx-0’ 디렉터리에서 ‘rx’는 수신(Receiver)을 의미하며, 디렉터리 안에는 수신 관련 큐 설정 파일이 들어있습니다. ‘tx-0’ 디렉터리에서 ‘tx’는 전송(Transmitter)을 의미하며, 전송 관련 큐 설정 파일이 들어있습니다.
RPS 설정 확인
$ sudo cat /sys/class/net/<device>/queues/rx-0/rps_cpus
0000
RPS 설정은 ‘rx-0’ 디렉터리에 있는 ‘rps_cpus’ 파일을 열어보면 알 수 있습니다. 위 예시 결과에 나온 ‘0000’은 ‘0000 0000 0000 0000’을 의미하며, 비활성화(Disable) 상태라는 뜻입니다. (기본적으로 비활성화 상태입니다. 4코어인 경우에는 ‘0’, 8코어인 경우에는 ’00’, 16코어인 경우에는 ‘0000’이 출력됩니다.)
RPS 적용
sudo echo "1001" > /sys/class/net/<device>/queues/rx-0/rps_cpus
0번과 12번 코어가 수신 패킷을 처리한다는 의미를 2진수로 표현하면 ‘0001 0000 0000 0001’이 됩니다. 이를 16진수로 변환하면 ‘1001’이 되며, 이 값을 ‘rps_cpus’ 파일에 업데이트했습니다.
수신 패킷 처리 코어를 2개로 설정한 결과
파드 1개
파드 1개로 테스트한 결과, 30,000TPS에서 여전히 문제가 발생했습니다. 수신 패킷은 코어 2개가 분산해서 처리하는 것을 확인할 수 있었지만, 서버 전체 성능 자체는 개선되지 않았습니다.
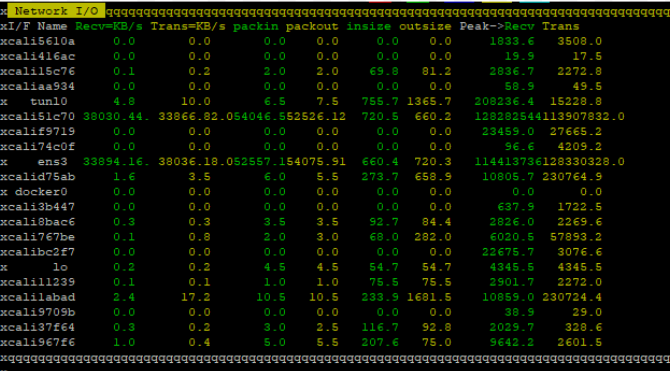
‘nmon’ 명령어로 네트워크 입출력을 모니터링한 결과, 1개 인터페이스에서 패킷을 처리하고 있음을 확인할 수 있었습니다.
파드 5개
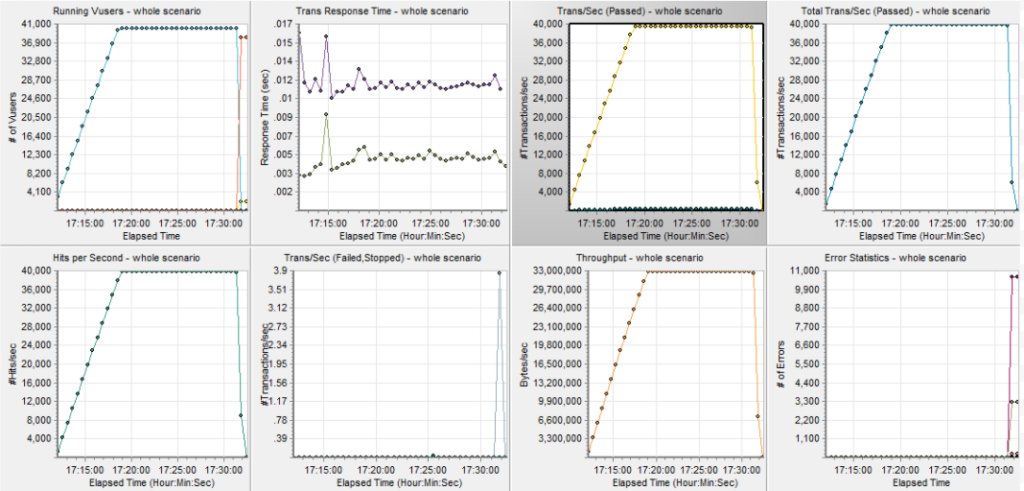
파드를 5개까지 늘려서 테스트한 결과, 40,000TPS까지 처리할 수 있었습니다.
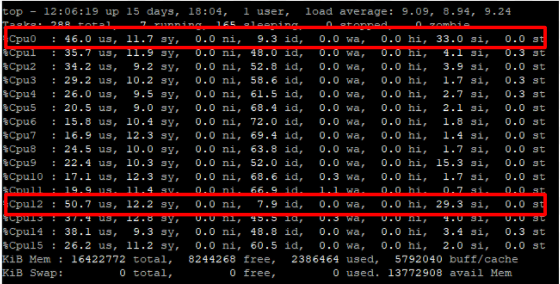
‘top’ 명령어로, RPS를 설정한 0번과 12번 코어에 패킷 처리가 분산돼, CPU 전체 부하도 분산되는 것을 확인할 수 있었습니다.
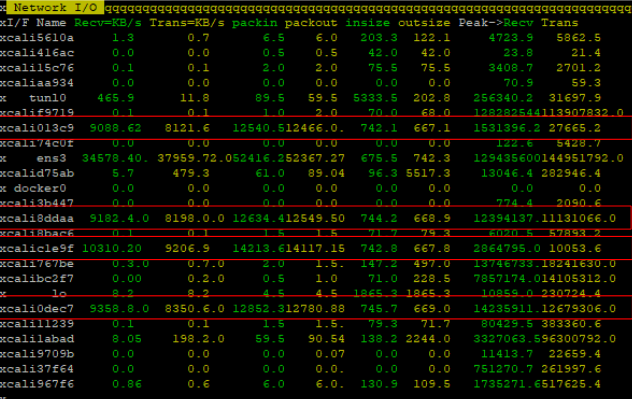
‘nmon’ 명령어로 네트워크 입출력을 모니터링한 결과, 4개 인터페이스에서 패킷을 분산해 처리하고 있음을 확인할 수 있었습니다.
RPS 설정으로 네트워크 부하를 분산하라
위와 같은 현상은 자주 발생하는 현상이 아닙니다. 일반적으로는 네트워크 전송과 수신 부하보다 애플리케이션 서버 로직 부하로 인해 CPU 사용량이 많이 늘어납니다. 마침, 위 사례에 나온 서버가 API 라우트(Route) 기능을 주로 수행하다 보니, 다른 서비스에 비해 네트워크 부하 비중이 높아서 발생한 것입니다.
만약 애플리케이션 로직 부하보다 네트워크 부하가 많다고 판단되는 서비스에서 비슷한 현상을 겪고 계신다면, RPS 설정은 적절한 튜닝 포인트(Tuning Point)가 되실 수 있으리라 생각합니다.