안녕하세요, 넷마블 빅데이터실 데이터엔지니어링팀 이재호입니다.
앞 글에서 고가용성 시스템을 구축하기 위해, 신뢰성 높은 데이터 파이프라인을 설계하고 구성하는 방식에 대해 살펴봤습니다. 이번 글에서는 복잡도를 관리하기 위한 요소에 대해 살펴보겠습니다.
복잡도를 관리하기 위한 고려 요소
데이터 파이프라인 시스템 복잡도를 관리하기 위해 아래와 같은 요소를 고려해야 합니다.
- 소스 타입: 인풋 데이터를 가져오는 방식 및 소스 스토리지 타입에 따라 발생할 수 있는 다양성.
- 데이터 형태: 인풋 데이터의 모델/포맷/스키마와 같은 형태적 특성 및 오염도에 따라 발생할 수 있는 다양성.
- 가공 방식: 데이터 오염도와 사용자 요구사항에 따른 전처리 프로세스 별 로직 내에서 발생할 수 있는 다양성.
- 전달 채널: 데이터 사용자에게 데이터를 전달하기 위한 접점 시스템의 종류에서 발생할 수 있는 다양성.
- 운영 도구: 시스템 내부 정보 또는 제어 방식을 노출할 때 인터페이스에서 발생할 수 있는 다양성.
각 고려 사항으로 언급한 다양성을 검토한 후에는 개별 케이스가 갖는 공통적인 특성이나 의미를 추출해야 합니다. 예를 들어, 소스 타입이 HDFS든지 Cassandra(카산드라)든지 우리는 데이터 소스로부터 읽기(read), 쓰기(write), 삭제(delete) 같은 요청을 할 것이라고 예상할 수 있습니다. 각각 내부적으로 처리하는 방법이 상이하고 복잡할 수 있지만, 우리는 이것들을 추상화(Abstraction)해 데이터 소스(DataSource)라는 인터페이스로 정의할 수 있습니다.
추상화 작업을 거치면구현 단계에서 발생하는 복잡도를 프레임워크로부터 분리할 수 있고, 신규 데이터 소스를 추가해도 복잡도를 유지할 수 있습니다. 이 접근 방식을 시스템 모듈 모든 곳에 적용했으며, 이를 기반으로 프레임워크 수준에서 일관성 있는 운영 모델을 지원할 수 있습니다.
- DataWrapper 인터페이스를 통해 데이터 형태가 달라지더라도 동일한 방식의 key, value 입출력 지원.
- TransformRule 인터페이스를 통해 가공 방식을 연산자의 순열로 정의한 후 동일한 형태의 호출 방식 지원.
- Channel 인터페이스를 통해 이기종(heterogeneous) 사용자 데이터베이스에 대한 동일한 전달 처리 방식 지원.
이렇게 추상화한 후에는 각 모듈이 특정한 형태로 아웃풋을 보장합니다. 그래서 이후 개발 과정에서 그 모듈을 믿고 사용할 수 있으며, 관리자가 모듈 별 세부 로직을 제어할 때에는 그 부분을 설정으로 분리하는 방식으로 시스템 복잡도를 관리할 수 있습니다. 특히, 이런 방식은 데이터 가공 단계에 필요한 사용자 별 요구사항과 각 사용자 별 전달 채널을 모두 충족할 수 있다는 장점이 있습니다.
데이터 가공
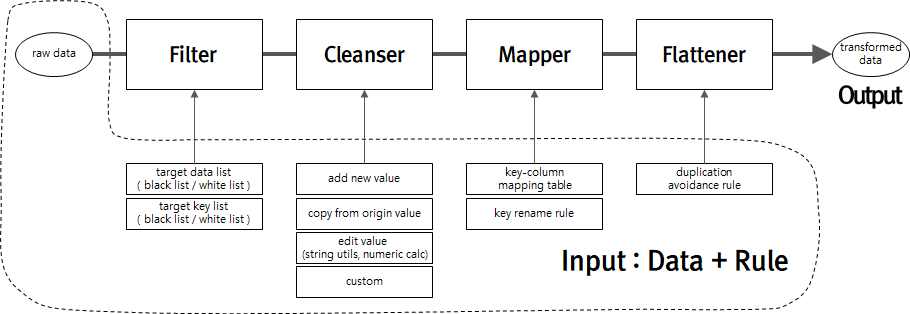
위 그림은 데이터 가공 단계를 처리하는 각 단계와 그 단계 별로 필요한 설정을 보여주는 구조도입니다. 목적 달성에 필요한 로직을 일련의 모듈로 추상화하고, 모듈을 chaining해 최종 데이터를 산출하는 방식으로 설계했습니다.
데이터 가데이터 가공 단계 모듈의 기능과 설정 방식
각 모듈의 기능과 설정 방식은 아래와 같습니다.
- Filter: 사용자가 원하는 데이터에서 원하는 컬럼만 추출하는 모듈입니다. 필터링하는 데이터와 컬럼은 각각 blacklist와 whitelist 기반으로 관리합니다.
- Cleanser: 새로운 값을 추가하거나 기존 값을 복제 또는 수정하는 모듈입니다. 각각 추가(add), 복사(copy), 편집(edit) 룰로 관리합니다. 편집은 값(value) 타입별 연산자 순열로 구성합니다.
- Mapper: 데이터에 있는 key별 값을 사용자에게 제공하는 테이블에 있는 컬럼과 매핑하는 모듈입니다. 사용자가 입력한 constant값으로 직접 매핑하거나 원래 key를 변형하는 룰 조합으로 구성합니다.
- Flattener: 중첩 구조 데이터를 depth가 없는 형태로 변형하는 모듈입니다. 중첩 제거 과정에서 중복키가 발생하면 처리 방식에 대한 정책 및 정책별 파라미터값으로 구성합니다.
채널별 데이터 전달 방식
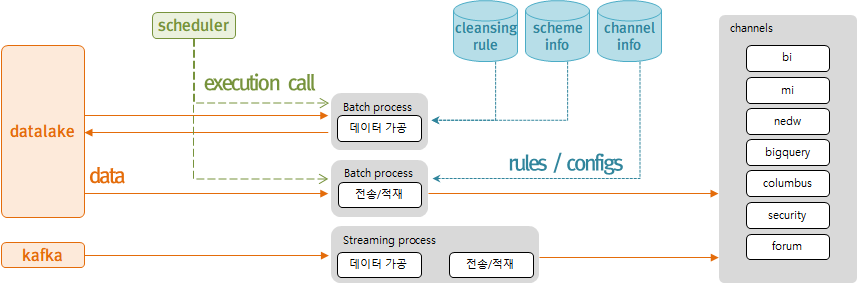
위 그림은 데이터 가공부터 채널 전달까지를 표현하는 실행 구조도입니다. 목적에 따라 스케줄러에 의해 별도 프로세스로 실행하거나 스트리밍으로 한번에 실행할 수 있습니다. 우리는 Channel이라는 인터페이스를 통해 다양한 채널을 공통으로 처리할 수 있습니다.
추상화한 모듈과 컴포넌트를 기반으로 대부분 상세하고 복잡한 처리를 감출 수 있습니다. 관리자는 단순화한 인터페이스로 데이터 파이프라인을 제어할 수 있습니다. 일반적인 절차는 default 설정을 통해 자동화할 수 있고, 필요시에는 관리자가 다르게 설정을 변경할 수 있습니다. 또한, fault 케이스 별로 fail-over 처리 레벨을 구분함으로써 아래와 같이 데이터 파이프라인 제어 구조를 단순화시킬 수 있습니다.
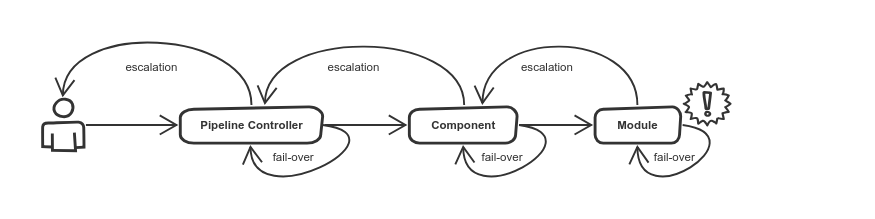
각 모듈이나 컴포넌트는 자신의 상위 객체에게 deterministic한 성공 결과를 제공할 수 있어야 합니다. 맡은 작업을 처리하는 과정에서 예상되는 fault를 각 모듈이나 컴포넌트가 스스로 극복할 수도 있지만, 그렇지 못한 경우에는 부분적인 실패를 남기지 않고 상위 객체에게 알려줘야(escalation) 합니다. 상위 객체도 이 과정을 재귀적으로 수행하며, 최종적으로도 해소가 안 되는 경우에는 관리자가 직접 처리할 수 있도록 알람을 보낼 수 있습니다.
파이프라인 컨트롤러는 관리자에게 매뉴얼 실행을 위한 커맨드와 세부 설정을 위한 메타 스토어를 제공하며, 아래와 같이 구성되어 있습니다.
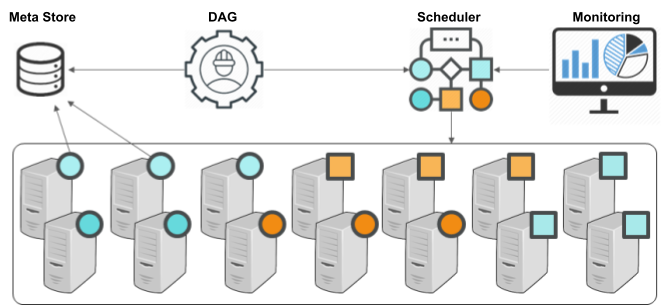
스케줄러(Scheduler)는 Airflow(에어플로우) 기반으로 동작하는 실행 계획(execution planning)과 YARN 기반으로 동작하는 RM(resource management)을 포괄하는 개념입니다.
스케줄러는 파이프라인 전체 태스크의 실행 순서를 제어하고, 각각 리소스를 할당하는 역할을 합니다. BigPi 로그 처리 시스템은 메타 스토어를 참조해 스케줄러가 실행할 DAG(Dynamic Acyclic Graph)를 자동으로 생성해주며, 실행하는 컴포넌트와 내부 모듈도 메타 스토어를 참조해 세부 설정 값을 구성합니다. 또한, 파이프라인 컨트롤러가 제공하는 여러 가시화 도구를 통해 시스템의 현재 상태를 직관적으로 확인할 수 있습니다.
시간이 지나도 유효할 수 있는 기본 원리와 원칙
지금까지 넷마블에서 데이터를 어떻게 사용하고, 그에 따라 어떤 방식으로 데이터 파이프라인을 구성하는지 소개해드렸습니다. 그 과정에서 해결해야 했던 분산 환경 이슈와 시스템 복잡도 문제를 다뤘고, 그와 관련되는 시스템 디자인 원칙도 살펴봤습니다.
거듭 말씀드리지만, 이 내용은 온전히 넷마블의데이터 환경과 조직 운영 방식에 적합하도록 설계된 결과물입니다. 이 설계는 머지 않아 새로운 환경에 대응하기 위해 바뀔 것이고, 그 상황에 맞는 새로운 솔루션이 있을 것입니다. 다만, 설계 과정에서 고려했던 기본적인 원리와 원칙은 시간이 지나더라도 유효할 것이라고 믿습니다.
Appendix – System Design Principles
(ref. Designing Data-Intensive Applications)
1. Reliability – 신뢰성
하드웨어나 소프트웨어 결함(fault) 또는 휴먼 에러가 발생할 때에도 시스템이 지속적으로 정확하게 작동하도록 보장하는 것을 의미합니다. 내고장성(fault-tolerance)을 보장하는 기법을 이용해, 알려져 있는 유형이나 결함을 해소할 수 있습니다. Reliability를 높이려면 아래와 같은 작업이 필요합니다.
- 시스템에서 발생하는 인터랙션과 가정하고 있는 사항에 대해 주의 깊게 검토.
- 모든 프로세스는 부분 실패를 인지해 crash를 일으키고, 재시작할 수 있도록 해야 함.
- 에러 가능성을 최소화할 수 있는 잘 설계된 Abstraction, API, 관리자 인터페이스를 통해 시스템의 올바른 사용 방식을 유도하고, 잘못된 방식을 억제해야 함. 단, 과도한 제약은 사용자가 제공된 인터페이스를 우회하도록 유인하기 때문에 적절한 밸런스가 중요.
- 휴먼 에러 가능성을 상정하고, 장애 영향도가 최소화 되도록 설계해야 함. 새로운 코드의 배포나 설정 변경을 점진적으로 진행할 수 있고, 장애 발생 시 빠른 롤백을 할 수 있도록 해야 하며, 잘못 처리된 데이터에 대해 쉽고 정확한 재처리 도구를 제공해야 함.
- 상세하고, 명확한 모니터링을 구축해야 함. 퍼포먼스 메트릭, 에러율 등에 대한 모니터링을 통해 위험 신호를 감지할 수 있고, 어떤 가정이나 제한사항들이 깨졌는지 여부를 체크할 수 있으며, 시스템 진단에도 사용할 수 있음.
- 시스템에 몇 가지 보장해야 하는 것이 있다면, 이를 지속적으로 체크해 모순되는 부분이 발견되는 즉시 경고 알림(alert)을 발생시켜야 함.
2. Scalability – 확장성
시스템 규모를 확장할 때 부하(데이터 량, 트래픽, 복잡도 등)가 증가하더라도 좋은 성능을 유지하는 전략 갖는 것을 의미합니다. 병렬 처리 가능한 로직을 적용하거나 분산 처리를 통해 시스템을 확장 가능(scalable)하게 만들 수 있습니다. Scalability를 논의하기 위해서는 부하(load)와 성능(performance)을 양적으로 서술할 수 있는 방법이 있어야 합니다.
- 반응 시간 백분위를 통해 성능을 측정할 수 있음.
- 고부하 상황에서도 안정성을 유지할 수 있는 최대 처리 가능량(processing capacity)을 추가할 수 있음.
3. Maintainability – 유지보수성
다양한 측면으로 이해할 수 있지만, 본질적으로는 이 시스템을 담당하는 개발팀, 운영팀, 데브옵스 팀의 삶을 더 좋게 만드는 것을 의미합니다. 이를 달성하기 위한 세부적인 디자인 원칙은 Simplicity(단순성), Evolvability(발전성), Operability(운영성)가 있습니다.
Simplicity – 단순성
시스템 구조 또는 소스코드의 복잡도를 낮은 수준으로 관리하는 것을 의미합니다. 좋은 Simplicity는 새로운 엔지니어가 시스템을 이해하기 쉽게 해줄 수 있습니다. 아래와 같은 복잡도 요소를 제거하면 Simplicity를 향상시킬 수 있습니다.
- 상태 공간(state space) 급증
- 모듈간 강한 커플링(tight coupling)
- 복잡하게 얽힌 종속관계(tangled dependencies)
- 일관성 없는 네이밍과 용어(terminology)
- 성능 문제 해소를 위한 수정(hack)
- 이슈들을 다르게 해결하기 위한 예외처리(special-casing)
나쁜 Simplicity는 유지보수를 어렵게 만들고 특히, 아래와 같은 문제를 유발합니다.
- 유지보수 단계에서 종종 비용과 일정이 초과될 수 있음.
- 복잡한 소프트웨어를 변경할 때는 버그를 만들어낼 위험이 더 큼.
- 시스템에 숨겨진 가정을 이해하고 추론하기 어려워질수록 의도하지 않은 결과와 예상치 못한 인터랙션이 더 쉽게 일어날 수 있음.
Evolvability – 발전성
시스템 구조 또는 소스코드를 변경하기 쉽도록 해주는 것을 의미합니다. 좋은 Evolvability를 통해 엔지니어는 변경된 요구사항이나 예상하지 못한 유스케이스에 더욱 유연하게 대응할 수 있습니다. 일반적으로 아래와 같은 요인으로 인해 시스템을 수정해야 하는 경우가 생깁니다.
- 새로운 것(fact)들을 학습
- 이전에는 예상하지 못했던 유스케이스가 발생
- 비즈니스 우선순위 변경
- 사용자가 새로운 변수(feature) 요구
- 새로운 플랫폼이 기존 플랫폼을 대체
- 법이나 정책적인 요구사항 변경
- 시스템 확장
데이터 파이프라인 및 내부 시스템을 편하게 변경하기 위해서는 시스템의 Simplicity가 높아야 하고, Abstraction이 잘 설계돼 있어야 합니다.
Operability – 운영성
운영 환경을 쉽고 편안하게 해주는 것을 의미합니다. 좋은 Operability는 반복적인 태스크를 쉽게 만들기 때문에, 운영팀은 높은 가치가 있는 활동에 노력을 집중할 수 있습니다. Operability를 향상시키기 위해 아래와 같은 작업을 해야 합니다.
- 좋은 모니터링을 통해 시스템 내부와 런타임 동작 상태에 대한 가시성(Visibility)을 제공.
- 표준화한 도구의 통합과 자동화를 잘 지원.
- 개별적인 머신에 대한 종속성을 제거해 부분적인 유지보수 시에도 서비스를 유지할 수 있어야 함.
- 양질의 문서와 이해하기 쉬운 운영 모델(“X를 하면 Y가 발생한다”와 같은)을 제공.
- 디폴트 동작/설정을 잘 제공하고 그러면서도 관리자가 기본값을 자유롭게 덮어쓸 수 있도록 해야 함.
- 적절한 곳에서는 자동 복구되고(self-healing), 필요한 경우 관리자가 시스템을 수동으로 조작할 수 있도록 해야 함.
- 예측 가능한 행동을 하도록 하고, 예상치 못한 행동(surprises)은 최소화 해야 함.