안녕하세요, 넷마블 빅데이터실 데이터엔지니어링팀 한우진입니다.
넷마블에서 퍼블리싱하는 다양한 게임을 원활히 운영하기 위해서는 시시각각 업데이트하는 게임 데이터를 분석해야 합니다. 정확한 의사결정을 위해 게임별로 다양한 지표를 추출해야 합니다. 이를 위해 시간별, 일자별 정제된 데이터가 필요합니다. Bigwave는 게임별 지표 작업을 위해 데이터를 적재하는 파이프라인을 부르는 프로젝트 명칭입니다. 지금부터 Bigwave의 발전과정을 소개합니다.
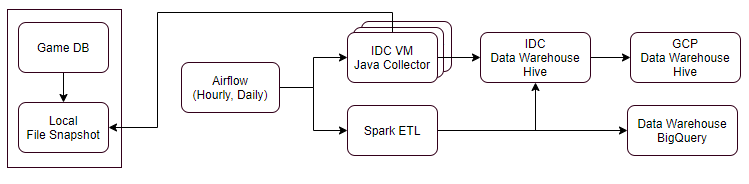
기존 데이터 파이프라인
먼저, 기존에 구성했던 데이터 파이프라인 환경을 살펴보겠습니다.
- IDC 서버 사용(게임별 적재용 서버 세팅 및 수동 할당)
- 스냅샷 파일 기반 처리(sftp) 또는 쿼리 방식 적재
- 게임별 수백개 ~ 수천개 테이블
- 메타관리: 구글 스프레드시트 수집대상 작성, DB 적용을 위한 서비스 API 사용해 Bigwave 수집정보로 사용
- 스케줄러 구성: 에어플로우(Airflow)에서 태스크 스크립트 생성시 테이블별 적재에 사용될 서버 할당
발생이슈
기존 데이터 파이프라인 환경에서는 운영과 관리 부분에서 이슈가 발생하면, 꾸준히 리소스를 소모하는 부분이 발생했습니다.
- 우선순위 적용이 어려움(에어플로우에서 태스크 순서를 수동으로 변경해야 함).
- IDC 서버 관리(게임별 해당 서버, 리소스 관리 등).
- 구글 스프레드시트의 메타 관리(지표 담당자가 내용을 수정하면 엔지니어링팀이 메타에 반영해야 함).
- 테이블별 순차 처리(에어플로우에서 DAG 중간에 1개 테이블이 실패할 경우 다음 테이블 수집이 정지됨).
- 테이블간 순서에 의존성은 없지만, 한정된 리소스 사용으로 병렬처리가 어려움.
요구사항 파악 및 이슈 해결 방안 모색
게임DB 적재를 개선하고 운영상 이슈를 관리하기 위해, 우선 데이터 파이프라인 개선을 위한 요구사항을 도출했습니다.
지표 추출을 위한 게임 DB 적재시간 단축
지표 추출을 위한 게임 DB는 시간별, 일자별로 적재하고 있으며, 신규런칭 서비스도 계속 추가됩니다.
기존
- 게임별 리소스 할당에 한계가 있기 때문에, 적재처리 속도를 높일 수 없음.
개선사항
- 리소스 매니저를 활용해 게임별 테이블 수에 따른 리소스 할당.
- 테이블 처리시 병렬처리가 가능한 구조로 변경.
게임별 적재에 사용하는 리소스 할당이 쉬워야 함
게임별 적재에 사용하는 수집 테이블 수가 계속 증가하고 있고, Daily ETL 서버는 새벽에만 사용합니다.
기존
- 태스크 실행시 SSH로 원격 접속해 해당 특정 테이블 ETL을 실행했던 탓에 자유롭게 리소스 할당을 못했음.
개선사항
- 컨테이너 기반으로 리소스 매니저를 사용하는 방향으로 진행(spark, dataproc).
지표 담당자가 담당 게임에 대한 정보를 쉽게 변경할 수 있어야 함
지표 담당자가 담당 게임에 대한 정보를 쉽게 변경할 수 있어야 하며, 메타데이터도 자동으로 반영할 수 있어야 합니다.
기존
- 구글 스프레드시트로 사용하는 메타 시트(meta-sheet)가 아닌 별도 메타 관리 서비스가 필요함.
개선사항
- 데이터플랫폼팀에서 제공하는 게임별 메타 관리 서비스(EDWCC)를 데이터 파이프라인에 적용 할 것.
에어플로우 스케줄에 테이블 수집 태스크 자동 반영
기존
- 태스크 자동 생성시 테이블 처리에 할당된 리소스 선택이 어려움.
- 수동으로 에어플로우 태스크를 등록해 우선순위 테이블을 업스트림(upstream), 다운스트림(downstream)으로 등록.
개선사항
- 리소스 매니저를 사용해 ETL 작업시 리소스 자동 할당.
- 파일 기반으로 DAG를 구성해 테이블 처리 순서를 병렬로 구성 후, 우선순위(priority)를 적용해 순서대로 적재 수행.
클라우드 환경으로 전환해 게임별 유연한 리소스 할당
기존에 사용하던 게임DB 적재 파이프라인은 게임별로 별도 서버를 할당해 처리하는 구조였습니다. 이런 구조는 수집 테이블 증가, 축소, 서비스 종료에 따른 리소스 할당을 어렵게 하고, 기존에 할당한 리소스 반납도 어려웠습니다.
일별(Daily) 배치를 돌리는 특성상 해당 서버는 새벽 시간대(00~05시, UTC+9)에만 리소스가 필요하기 때문에 해당 작업이 끝나면 리소스 할당이 없는 대부분 시간 동안 자원이 낭비됐습니다. GCP 환경을 사용하면서 일일 배치 실행 전 해당 게임DB 적재를 위한 전용 클러스터를 생성하고, 적재를 완료하면 클러스터를 삭제해 필요한 시간에만 리소스를 사용하는 구조로 변경했습니다.
추가로, 자바 애플리케이션으로 구성했던 ETL 작업을 스파크(spark)로 전환하면서 YARN 리소스 매니저를 사용할 수 있었던 덕분에, 병렬처리가 어려웠던 서버 할당 방식을 스케일 아웃(scale out)으로 병렬 처리해 적재완료 시간을 단축할 수 있었습니다.
GCP로 구축한 게임DB 적재 데이터 파이프라인
게임DB는 유저 데이터를 신속하게 분석하기 위해 시간별, 일별 배치 처리를 하고 있습니다. 수집이 필요한 테이블은 게임마다 수백개에서 수천개까지 다양하고 신규 게임 런칭, 서버 통합, 리전 통합 등 다양한 이유에 따라 필요한 리소스가 달라집니다. 이해를 돕기 위해 GCP 기반의 게임DB 적재 파이프라인 구성에 대해 간단히 소개하겠습니다.
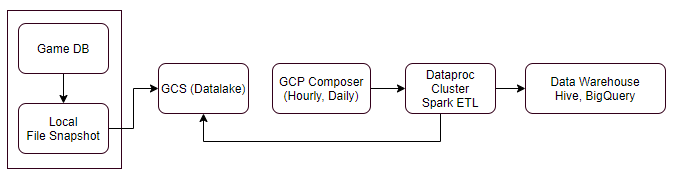
Source: MSSQL, MySQL
ETL: Dataproc, Spark
Scheduler: GCP Composers
Data Warehouse: Hive, BigQuery
위 그림은 현재 사용중인 GCP 기반 게임DB 적재 파이프라인을 단순화한 구성도입니다. 적재 대상인 게임DB는 게임 운영 데이터, 유저, 아이템, 던전 등의 데이터를 DB에 업데이트하고 있습니다. 적재주기는 지표 생성 목적에 따라 시간별, 일별로 수집하는 테이블이 다릅니다. 정해진 주기마다 수집 대상 테이블 파일 스냅샷을 GCS로 업로드하고, 스케줄러에서 특정 게임 테이블을 기준으로 스파크 잡(Spark job)을 실행해 GCP 하이브(Hive)와 빅쿼리(BigQuery)에 적재하고 있습니다.
GCP 게임DB 데이터 파이프라인 요구사항
GCP 게임DB 데이터 파이프라인 구축 시 요구사항은 아래와 같습니다.
DB 스냅샷 생성
서비스중 수집 대상 테이블에서 데이터를 계속 업데이트하는 상황이 있기 때문에, 특정 시간 구간에 있는 데이터를 DB 스냅샷 파일로 생성해 더이상 변하지 않는 상태로 만들어 데이터 파일을 생성합니다.
스냅샷 생성시 ETL을 위해 사전에 약속된 형태로 파일을 생성합니다.
GCS 스냅샷 업로드
DB 로컬 파일에 생성한 스냅샷 파일을 GCP 클라우드에서 처리하기 쉽도록 사전 약속된 GCS 경로에 업로드합니다. 경로는 버킷명/게임코드/날짜/스냅샷 파일명으로 업로드합니다.
초기 적재후, 요청사항에 따라 데이터를 재처리하기 위해 GCS에 10일까지 보관후 삭제합니다.
스케줄러
에어플로우의 GCP 버전인 컴포저(Composer)를 사용해 시간별, 일별 적재를 수행합니다.
일별 적재 수행시 게임별 별도 데이터프록(Dataproc) 클러스터를 생성해 게임별 클러스터에 스파크 잡(spark job)을 제출합니다. 일별 적재를 완료하면 해당 클러스터는 삭제합니다.
클러스터 생성
게임마다 수집 대상 테이블 수가 다르기 때문에 리소스 할당이 달라야 합니다. 게임별 데이터프록(Dataproc) 클러스터 워커(worker) 노드수를 다르게 조절해 리소스를 할당하고, 적재를 완료하면 클러스터를 삭제해 불필요한 리소스를 반납합니다.
Spark ETL
- Extract: GCS에 업로드한 스냅샷을 데이터프록(Dataproc) 클러스터에 있는 스파크(Spark)로 불러옵니다.
- Transform: 테이블마다 필요한 증분처리, 조건절, 컬럼 추가 등 transform을 진행합니다.
- Load: 가공한 데이터를 하이브(Hive)와 빅쿼리(BigQuery) 파티션 테이블로 적재합니다.
Data Warehouse
- 하이브(Hive): 하이브 익스터널 테이블(hive external table) 설정으로 GCS에 적재한 ORC 파일을 로케이션(location)으로 사용합니다. GCS에 적재한 ORC파일은 보관기간이 별도로 없는 영구 저장 대상입니다.
- 빅쿼리(BigQuery): 프로젝트마다 설정한 빅쿼리 데이터셋(BigQuery dataset)으로 날짜별 파티션 테이블로 저장합니다.
에어플로우 스케줄러 DAG 구성 변경
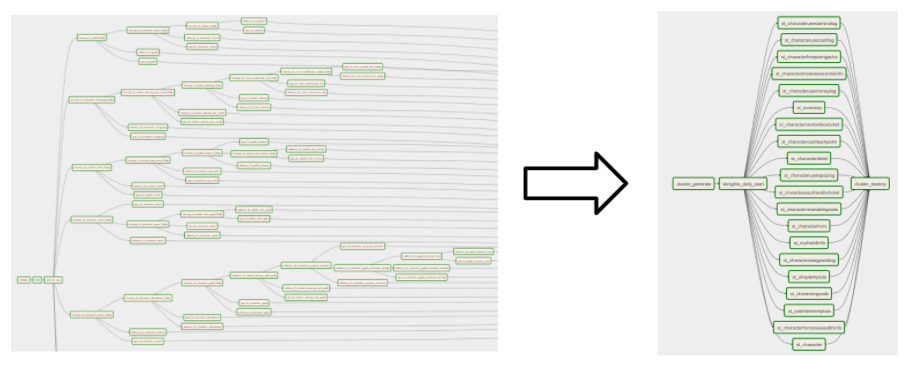
위 그림은 에어플로우 DAG에서 수집 태스크 구성을 변경한 결과입니다. 기존에는 게임별 처리 리소스에 제한이 있어 테이블별로 순차적 DAG를 수동으로 구성해 테이블 처리 우선순위에 따라 스케줄을 실행했습니다.
하지만, ETL을 GCP 환경으로 변경한 후, 데이터프록(Dataproc)기반으로 스파크(Spark) ETL 환경으로 전환하면서 리소스 매니저를 활용할 수 있었습니다. 그 결과 태스크 자동구성과 병렬처리를 할 수 있게 됐습니다.
또한 에어플로우에 우선순위(priority)를 설정해, 병렬로 태스크를 실행해도 우선순위에 따라 태스크를 실행하는 구조로 변경할 수 있었습니다. 기존 DAG 구성에서는 태스크를 생성하면 코드기반으로 업스트림과 다운스트림을 수동 구성해야했지만, 변경한 구조에서는 메타데이터를 참조한 파일을 생성해 태스크를 자동으로 생성하는 구조로 개선됐습니다. 이를 통해, 운영상 편리함과 동시 처리로 인한 적재 처리 시간 단축이라는 효과를 볼 수 있었습니다.
사용자 셀프 ETL 구성 서비스 준비
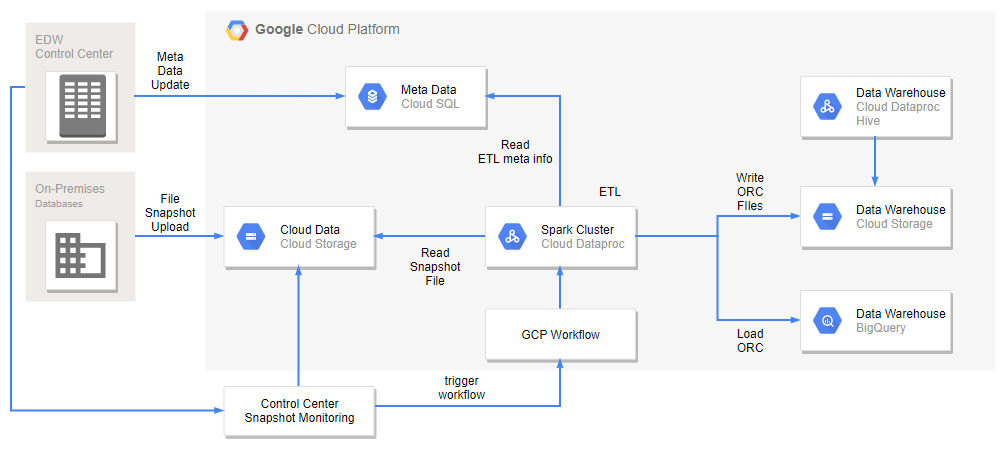
넷마블는 빅데이터실 이외 다른조직에서도 데이터 분석에 대한 요구가 있습니다. 현재는 해당 부서에서 필요한 데이터가 있을시, 별도 적재 구성을 요청하는 프로세스로 진행하고 있습니다. (넷마블 개발사에서 자체적으로 분석하기 위해 별도 적재 요청을 하는 경우가 지속적으로 증가하고 있습니다.) 이런 외부 요청에 맞춰 사용자가 셀프 구성할 수 있는 서비스를 준비하고 있습니다.
아래 그림은 기존 자체 스케줄러를 구성해 실행하는 데이터 파이프라인입니다. 셀프 구성 ETL 서비스에는 스케줄러를 별도로 구성하지 않고, 파일 스냅샷 상태에 따라 적재를 실행하는 트리거 방식으로 서비스를 구성할 계획입니다. 필요한 부서나 개발사에서 자체 스케줄러를 구성해 호출하거나, 스냅샷을 GCS에 업로드하면 자동으로 ETL 잡을 실행해 별도 스케줄러를 구성하지 않아도 되도록 준비하고 있습니다.
AS-IS

TO-BE
지속해서 변화할 데이터 파이프라인
여기까지 넷마블에서 게임DB를 적재하는 데이터 파이프라인이 요구사항에 따라 변화한 과정을 소개했습니다. 요구사항을 정리하고 해당 이슈를 해결하기 위한 신규 파이프라인을 구성하는 과정을 정리하며 Bigwave 프로젝트를 다시 한번 바라볼 수 있었던 시간이었습니다.
현재 사용하고 있는 데이터 파이프라인은 앞으로도 요구사항이 변화하는 추세와 기업 상황에 맞게 지속해서 개선할 수 있도록 대응할 것입니다.