안녕하세요, 넷마블 QA실 QA시스템팀 이동근입니다.
스프링 부트 3.0 네이티브 이미지를 쿠버네티스에 적용했던 후기글(쿠버네티스가 스프링 부트 3.0 네이티브 이미지를 만났네) 이후, 두 번째 글이네요. 이번에는 쿠버네티스 파드 클러스터링 방법과 활용 예시를 공유해 드립니다.
쿠버네티스
쿠버네티스는 대표적인 무상태(Stateless) 아키텍처 시스템입니다. 새로 생성된 파드는 이미 생성된 이전 파드에게 영향을 주지도 않고, 이전 파드에서 영향을 받지도 않습니다. 그렇기 때문에 급증하는 트래픽에 스케일아웃으로 원활히 대응하는 큰 장점을 가지고 있습니다. MSA(Microservice Architecture)로 구성한 시스템이라면 적극적으로 적용하기 좋습니다. 제가 담당하는 크래시리포트 또한 쿠버네티스를 사용하고 있으며, 트래픽에 기반한 HPA(Horizontal Pod Autoscaling)를 사용하고 있습니다. 하지만, 여러 파드 중에 일부 파드에서만 기능을 활성화하거나, 주변 파드에서 생성한 데이터를 공유해야 할 기능이 필요하다면 추가 설정을 해야 합니다.
서비스 디스커버리
크래시리포트 서비스 아키텍처를 모놀리식(Monolithic)에서 MSA로 변경하는 과정에서 부하 분산을 위해 신규 인스턴스를 추가할 때, 이를 전체 서비스 목록에 자동으로 추가하고 트래픽을 전달하는 자동화 절차가 필요했습니다.
서비스 디스커버리 구현 패턴에는 클라이언트 기반 패턴과 서버 기반 패턴이 있습니다. 클라이언트 기반 패턴에서는 Spring Cloud Netflix Eureka가, 서버 기반 패턴에서는 쿠버네티스가 대표적인 오픈 소스(OSS)입니다.
본 글에서는 쿠버네티스 서비스에서 제공하는 서비스 디스커버리 절차를 사용해 파드 클러스터링을 구성하고 실시간 스트리밍 서비스 구성과 캐시 데이터 공유를 통한 메시지 처리 성능을 개선해 보려 합니다. 이를 적용한 애플리케이션 두 가지에 대해서 좀 더 자세히 알아보겠습니다.
크래시리포트 실시간 5분 통계 기능
크래시리포트에서는 최근 5분간 발생한 데이터를 스트리밍 데이터 처리 기능을 활용해서 실시간으로 대시보드에 푸시해 사용자에게 제공하고 있습니다.
기존 서비스 구성의 한계
기존 구성은 실시간 데이터 생성을 위해 GCP(Google Cloud Platform)의 Dataflow를 사용했었습니다.
Dataflow는 서버리스 제품으로, 레디스(Redis) 인스턴스에 연결하고 푸시하는 절차가 복잡합니다. 또한 대시보드에서 웹소켓(Websocket) 구독을 연결하기에도 적합하지 않습니다. 그래서 ‘레디스에 푸시하는 기능’과 ‘레디스를 구독하고 웹소켓 서버를 구성하는 기능’을 위한 별도의 쿠버네티스 클러스터를 추가로 구성해야 했습니다.
다만, Apache Beam 기반인 Dataflow에 신규 데이터 항목을 추가하기 위한 학습량이 많았으며, 빈번한 Apache Beam 버전 업데이트와 GCP의 지원 만료 등으로 인해 유지보수의 어려움도 있었습니다. Dataflow를 대체할 수 있는 적절한 라이브러리를 이용해서 분산된 인스턴스들을 단일 쿠버네티스 기반 실시간 푸시 서비스로 재구성할 방법이 필요했습니다. (실시간 대시보드 푸시 기능을 구현한 기존 모습은 아래 그림을 참고해 주세요.)
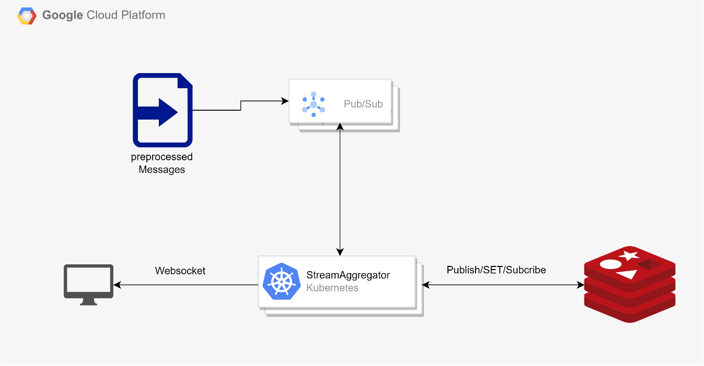
기존 구성에서 쿠버네티스는 다수의 파드가 Pub/Sub에서 수신하는 메시지를 Key/Value로 매핑 처리한 후 마스터 파드로 전달해 최종 값을 계산하도록 구성했습니다. 그리고 계산된 마지막 값을 레디스에 푸시해 웹소켓으로 구독 중인 대시보드에 전달했었습니다.
신규 구성
신규 구성에서는 Apache Camel과 스프링 부트(Spring Boot)를 활용했습니다. Apache Camel은 데이터를 수신하고 처리한 후 보내야 하는 목적지를 정의하는 데이터 경로 설정을 기반으로 애플리케이션을 생성할 수 있습니다.
파드 내에는 개별 메시지에 대한 사전 통계 계산을 하는 스트리밍 라우터와 사전 계산된 데이터를 기반으로 최종 통계를 계산하는 스트리밍 라우터로 구성했습니다. 결과적으로 하둡(Hadoop)의 MapReduce 아키텍처와 유사하게 구성했습니다. 스트리밍 처리 방법은 Apache Camel에서 제공하는 Camel Aggregation Strategy를 활용했습니다.
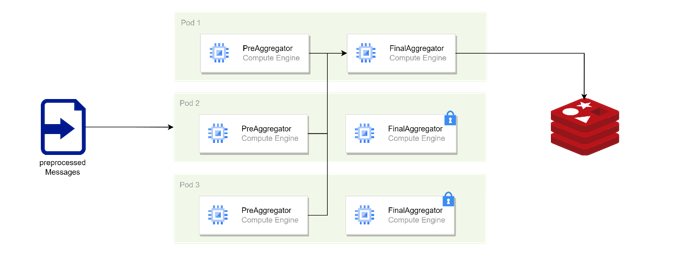
Apache Camel은 쿠버네티스 환경에서의 클러스터링을 지원합니다. Camel-Kubernetes는 마스터 노드(API endpoint)에서 제공하는 파드 정보를 활용해 클러스터 내에 서비스 디스커버리를 제공합니다. Camel-master는 쿠버네티스의 리스(Lease) 객체를 활용해 리더(Master)를 선출하고, Active – Standby 서비스를 구성할 수 있게 해줍니다.
리스(Lease)
리스(Lease)는 분산 시스템에서 공유 리소스를 잠그고 노드 간의 활동을 조정하는 메커니즘입니다. 쿠버네티스에서는 ‘리스’ 개념을 coordination.k8s.io API 그룹에 있는 리스 객체로 표현하며, 노드 하트비트나 컴포넌트 수준의 리더 선출 같은 시스템 핵심 기능에서 사용합니다.
Camel-kubernetes 클러스터링을 위해서는 다음과 같이 설정해야 합니다.
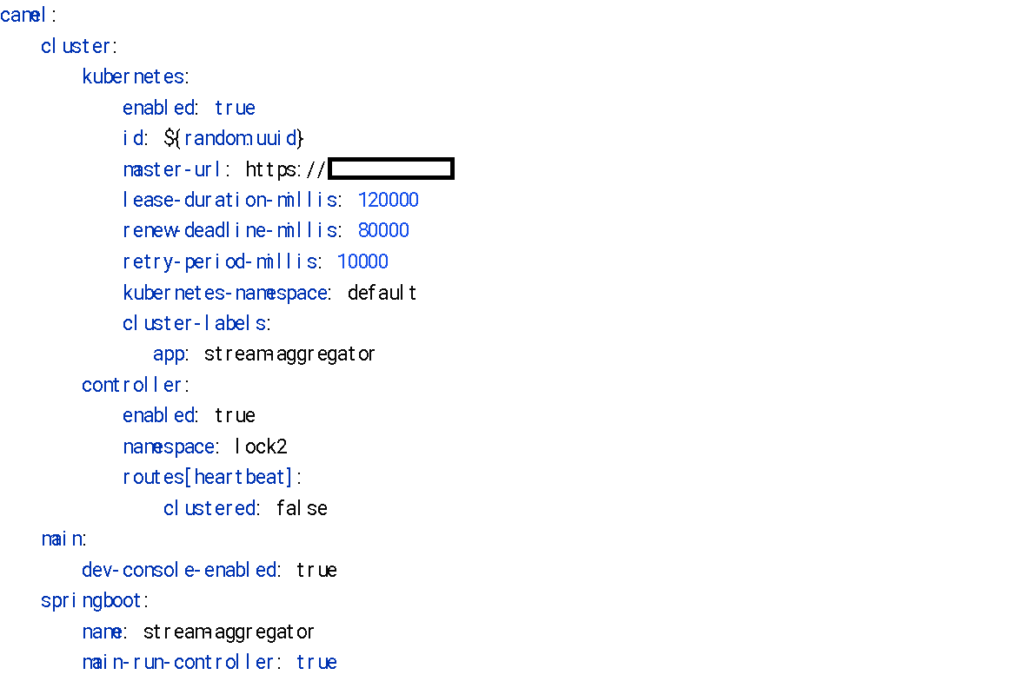
또한, 쿠버네티스 내 서비스 디스커버리와 리스 객체 점유를 위해서는 아래와 같이 계정과 권한을 설정해야 합니다.
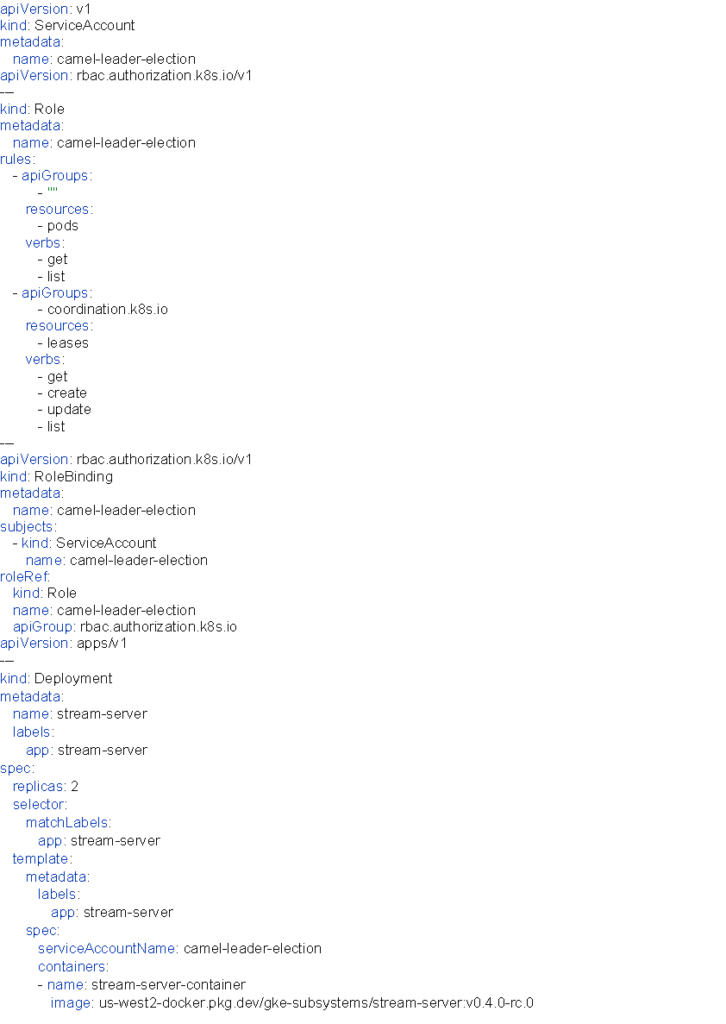
위 설정을 적용하면, 아래 로그에서 보이는 것처럼 클러스터 목록과 최초 선출된 리더를 확인할 수 있습니다. 또한, 최초 선정된 리더 파드를 종료하면서 기존 파드 목록 중에서 신규 리더가 선출되는 것도 확인할 수 있습니다.
2023-10-30 16:03:27.868 TimedLeaderNotifier - L:166 The cluster has a new leader: Optional[stream-aggregator-5c6b74f548-p672z]
2023-10-30 16:03:27.962 TimedLeaderNotifier - L:178 The list of cluster members has changed: [stream-aggregator-5c6b74f548-p672z, stream-aggregator-5c6b74f548-pjvsj]
2023-10-30 16:09:56.947 TimedLeaderNotifier - L:166 The cluster has a new leader: Optional[stream-aggregator-5c6b74f548-pjvsj]
2023-10-30 16:09:56.953 TimedLeaderNotifier - L:178 The list of cluster members has changed: [stream-aggregator-5c6b74f548-b4b7b, stream-aggregator-5c6b74f548-pjvsj]
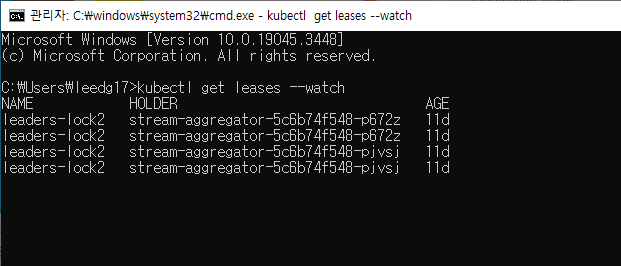
kubectl로 확인한 리더 변경 내역kubectl을 통해서도 리스 객체를 점유하고 있는 파드의 아이디를 확인할 수 있습니다.
$ kubectl get leases leaders-lock2 -o yaml
kubectl get leases leaders-lock2 -o yaml 명령어를 사용하면 좀 더 상세한 내용을 확인할 수 있습니다.
적용 결과
아래 그림은 신규 구성을 적용 이전과 이후의 현황입니다.
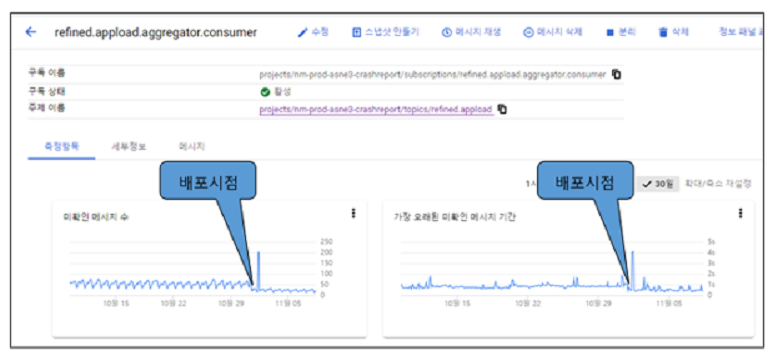
기존 구성만큼 안정적으로 서비스를 제공하면서, 기존 구성 대비 미확인 메시지 수와 가장 오래된 미확인 메시지 기간이 감소한 것을 확인할 수 있었습니다.
심볼리케이팅 캐시 데이터 공유
심볼리케이팅(Symbolicating)은 크래시리포트의 주요 기능 중 하나로, 크래시가 발생한 스레드(Thread)에서 나오는 백트레이스(BackTrace)에 포함된 프레임워크(Framework)의 내용을 사람이 읽을 수 있는 형태로 변환하는 작업입니다.
- Adding identifiable symbol names to a crash report | Apple Developer Documentation
- Diagnosing issues using crash reports and device logs | Apple Developer Documentation
- Crash Symbolication – Countly
심볼리케이팅 전/후에 대한 예시는 아래 이미지들을 참고해 주시면 됩니다.

기존 캐시 시스템의 한계
크래시를 수집하다 보면 동일한 크래시가 반복해서 수집되는 현상이 나타납니다. 같은 크래시가 수집되기 때문에, 발생한 프레임워크 이름과 메모리 주소 정보 등을 개별 파드 안에 캐시 데이터에 저장하고 재사용하면 심볼리케이팅 소요 시간을 단축할 수 있습니다. 하지만, 캐시 데이터를 각각 파드에 쌓아야 하기 때문에 모든 파드에 캐시 데이터를 쌓기 전까지는 캐시를 활용한 성능 개선에 한계가 있었습니다. 그래서 파드끼리 데이터를 공유해 캐시 데이터 수집 시간을 단축할 수 있다면, 캐싱 효율성을 높이고 신규 배포 시 캐시가 초기화되는 문제도 일정 부분 해소할 수 있어 보였습니다. 즉, 파드 클러스터링을 이용해서 개별 파드에 있는 캐시 데이터를 공유하도록 구성을 변경할 방법이 필요했습니다.
헤이즐캐스트(Hazelcast)
기존 구성에서는 embedded H2DB를 활용해서 JPA 기반 캐싱을 사용했습니다. 이 경우, 파드끼리 데이터를 공유하기 어려워 캐싱 효과를 보기가 어려웠습니다. 이를 해소하기 위해, 신규 구성에서는 헤이즐캐스트(Hazelcast)를 이용한 Key-Value 캐싱을 사용하기로 했습니다.
헤이즐캐스트를 활용하면 쿠버네티스 내 서비스 디스커버리를 간단한 설정만으로 클러스터링을 통한 데이터 공유를 쉽게 구성할 수 있습니다. 구체적인 서비스 설정은 다음과 같습니다.
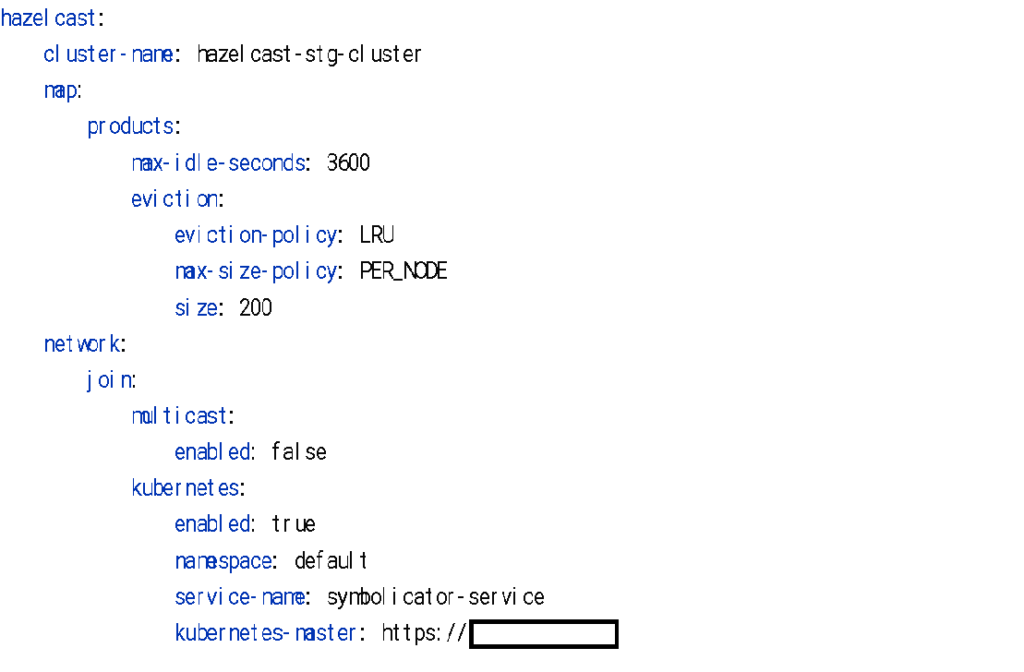
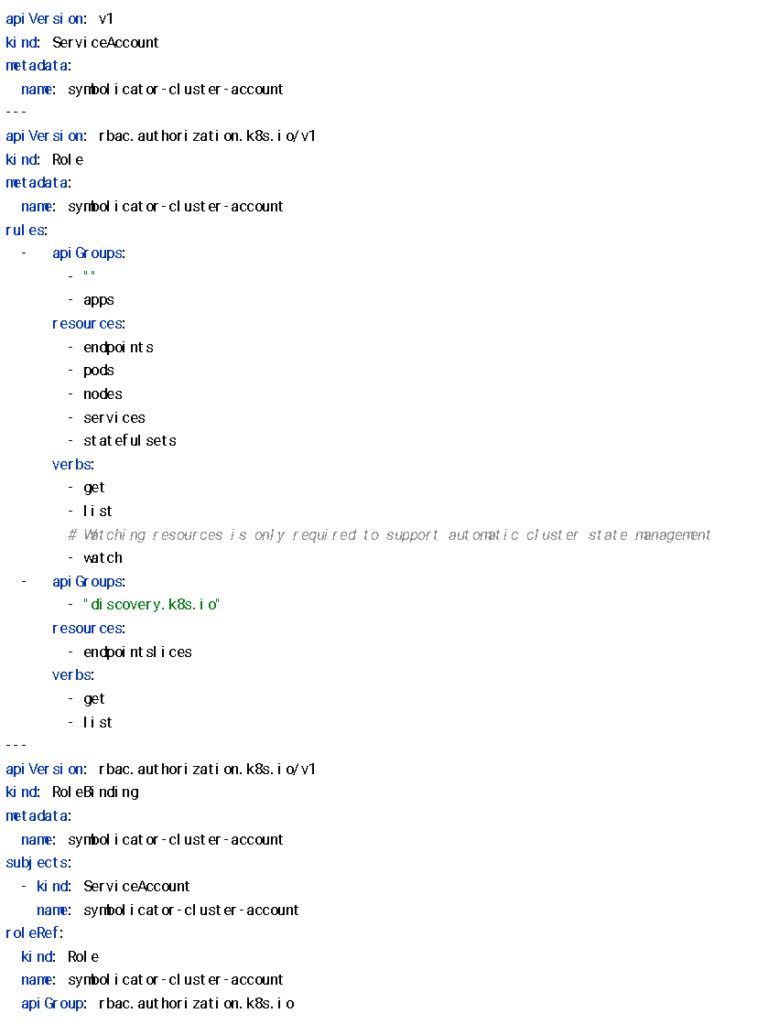
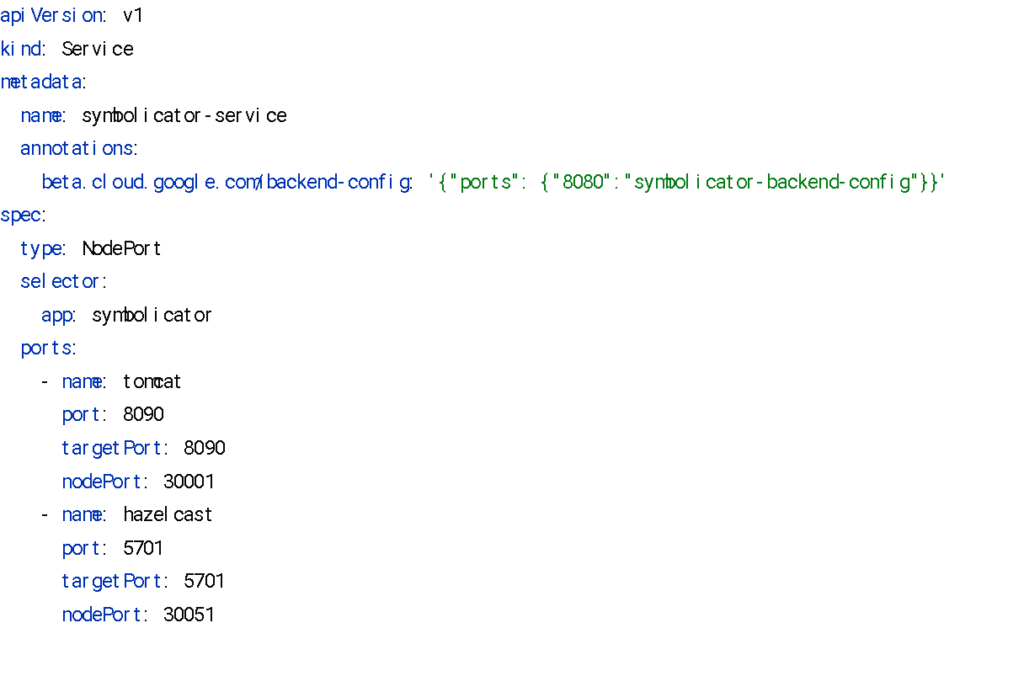
위 설정들을 적용 후 배포를 하면 아래와 같은 로그가 출력됩니다. 출력된 로그를 통해서 설정이 정상 작동하는 것을 확인할 수 있습니다.
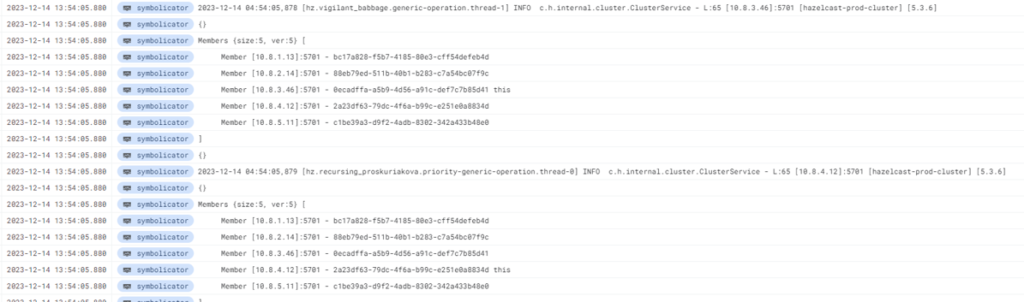
적용 결과
아래는 헤이즐캐스트 적용 이전과 이후를 비교한 화면입니다. 파드에서 발생한 캐시 데이터가 주변 파드의 캐시에 공유됨으로써, 크래시의 심볼리케이팅을 수행하는 평균 시간이 감소한 것을 확인할 수 있었습니다. 또한, 미확인 메시지 기간 값이 최댓값 기준으로 기존 대비 평균 50% 정도 성능 개선이 있었습니다.
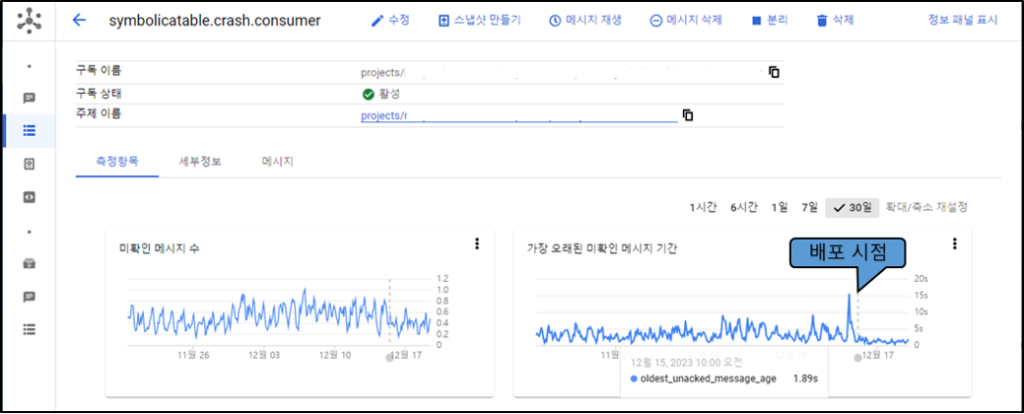
헤이즐캐스트는 쿠버네티스 배포 과정에서 기존 캐시 데이터를 신규 파드에 동기화하는 옵션을 제공합니다. 그 덕분에 신규 기능을 배포해도 기존 캐시 데이터를 유지할 수 있으므로, 배포에 따른 초기 성능 지연 문제도 해소할 수 있었습니다.
파드 클러스터링 설정을 마치고
쿠버네티스에서는 개별 파드에서 발생한 데이터가 주변 파드에 영향을 주지 않는 것이 기본 구성입니다. 하지만 사용자가 필요하다면 공유할 수 있는 방법을 제공하고 있습니다. Apache Camel과 헤이즐캐스트와 같은 오픈 소스들은 이미 쿠버네티스에서 제공하는 클러스터링 절차에 맞는 클러스터링 기능을 제공하고 있었습니다. 저는 이를 이용해 기존 구성에서 나오던 병목 부분을 적절히 해소할 수 있었습니다.
- 파드 클러스터링과 리더 선출을 통해서 MapReduce 아키텍처를 구성할 수 있었고, 이를 통해 실시간 스트리밍 데이터 처리 구성이 가능했습니다. 쿠버네티스가 갖는 스케일아웃의 장점을 유지하면서 실시간 통계 계산도 가능하게 되었습니다.
- 파드 클러스터링을 통해 캐시 데이터가 공유되도록 구성했습니다. 모든 파드에 캐시 데이터가 쌓이는 시간이 단축돼, 전체적으로 심볼리케이팅에서 소모하는 시간이 감소했습니다. 이는 메시지 처리량이 증대되는 개선으로 이어졌습니다.
저는 이번 기회에 파드 클러스터링 설정을 접하면서, 쿠버네티스에 대해서 좀 더 자세히 알게 됐습니다. 그리고 크래시리포트 시스템이 갖고 있었던, 작지만 작지 않았던 문제를 개선했습니다. 위 2가지 사례 외에도 클러스터링을 활용한 개선 사례는 더 있으리라 생각합니다. 이 사례들이 여러분의 시스템에 있는 작은 문제들을 해결하는 또 다른 방법 중 하나가 될 수 있으면 좋겠습니다.
<참고자료>
- https://catsbi.oopy.io/c95e714b-0d28-49d0-aff5-10acd5d0dce5
- https://spring.io/projects/spring-cloud-netflix
- https://cloud.google.com/dataflow?hl=ko
- https://cloud.google.com/dataflow/docs/support/sdk-version-support-status?hl=ko
- https://camel.apache.org/camel-core/getting-started/index.html#BookGettingStarted-Routes
- https://velog.io/@kimdukbae/MapReduce
- https://camel.apache.org/components/3.20.x/eips/aggregate-eip.html
- https://developer.broadleafcommerce.com/production/configuration/camel-cluster-service
- https://developers.redhat.com/articles/2021/09/23/leader-election-kubernetes-using-apache-camel#
- https://en.wikipedia.org/wiki/Lease_(computer_science)
- https://kubernetes.io/docs/concepts/architecture/leases/
- https://hcn1519.github.io/articles/2020-02/crash_report_symbolication
- https://support.count.ly/hc/en-us/articles/360037261472-Crash-Symbolication
- https://docs.hazelcast.com/hazelcast/5.1/kubernetes/kubernetes-auto-discovery#preventing-data-loss-during-upgrades